Truly understanding logistic regression - Part 4
In this final post, we will apply in practice the concepts we've discussed by implementing logistic regression using the ML.NET framework.
What is ML.NET ?
ML.NET is an open-source, cross-platform machine learning framework developed by Microsoft. It is designed to provide a simplified interface for integrating machine learning models into .NET applications. ML.NET enables developers to build custom machine learning models, as well as use pre-trained models for tasks such as classification, regression, clustering, and recommendation.
Developers can use ML.NET with languages such as C# and F# to build, train, and deploy machine learning models directly within their .NET applications. It simplifies the process of incorporating machine learning capabilities, making it more accessible to the broader .NET developer community.
What is the data ?
We will utilize the dataset sourced from Kaggle, in which various customer attributes such as country, gender, age, etc., are provided. The objective is to predict churn, i.e., whether the customer will leave the bank or not.
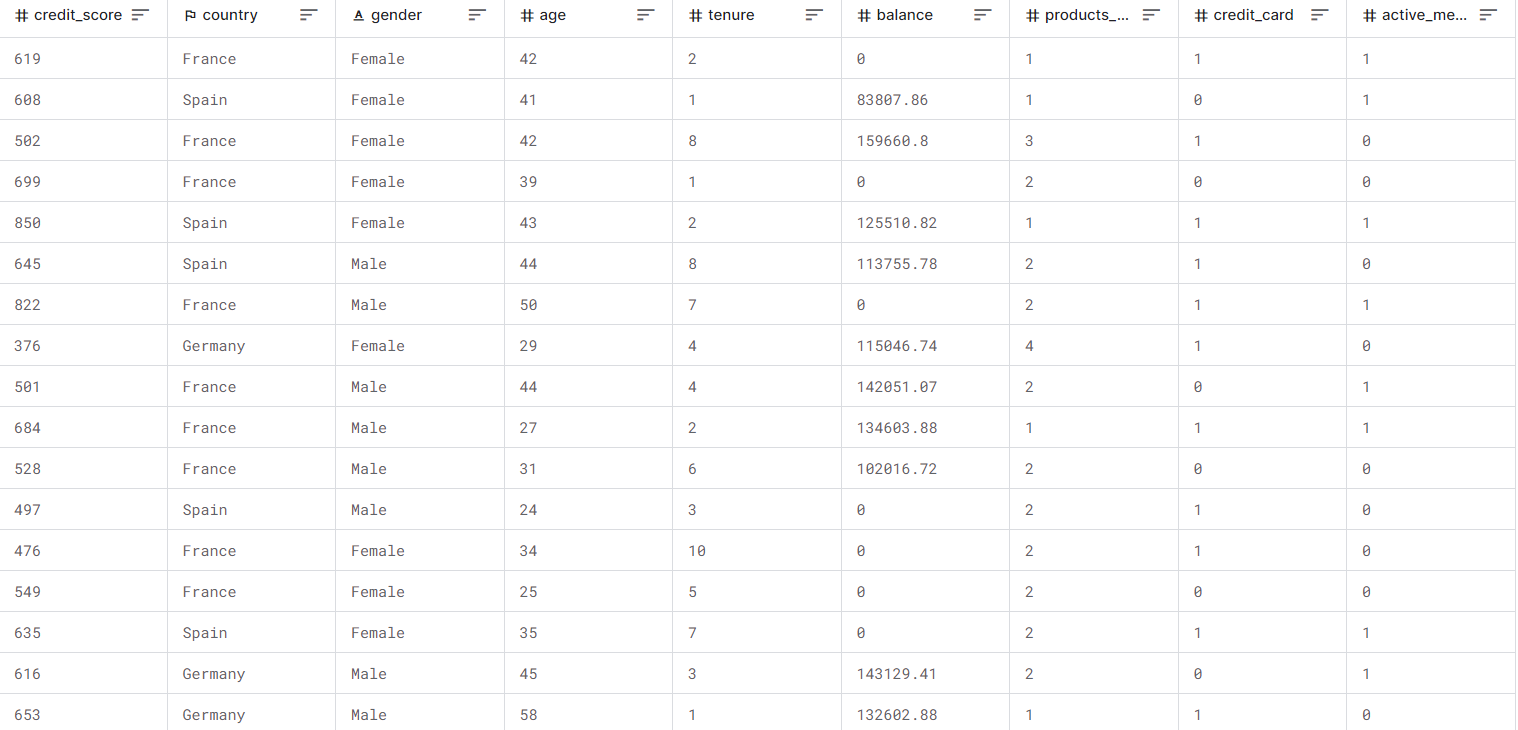
This problem is well-suited for logistic regression, given that the task involves classifying a customer into two possibilities based on certain input features.
Setting up the solution
In Visual Studio, create a new solution and name it EOCS.LogisticRegression for example.
In this solution, add a Console App named EOCS.LogisticRegression.Console and install the following NuGet package.
Configuring ML.NET
Now that all the components are set up, we can configure ML.NET and proceed to explore how it functions.
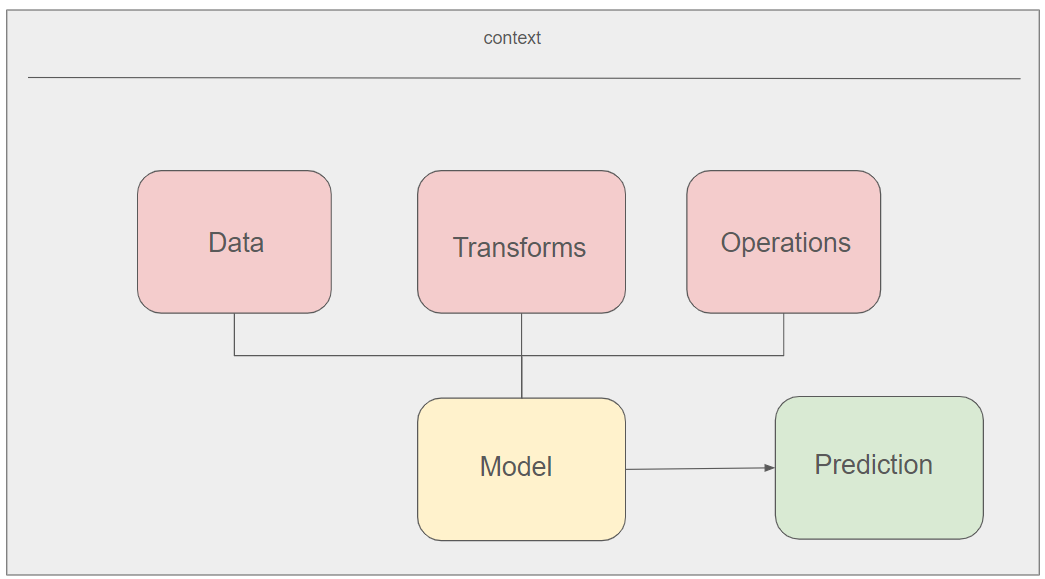
ML.NET endeavors to faithfully replicate the processes employed in machine learning.
Initially, one requires data (Data).
Based on the type of task (whether it's binary classification, regression, anomaly detection, etc.), we determine the operations (Operations) to be performed on this data.
Between the data and operations, it is often necessary to apply transformations (Transforms) such as normalization or standardization.
Finally, once all these components are in place, the training can commence, resulting in a model (Model) from which predictions can be made (Prediction).
In the remainder of this section, we will follow the above bullet points to observe ML.NET in action.
Defining the context
Add the following code in the Program class.
1var ctx = new MLContext();
Loading data
The data is currently in CSV format, and we can leverage ML.NET capabilities to easily process the file.
1// Load data from file
2var path = AppContext.BaseDirectory + "/dataset.csv";
3var data = ctx.Data.LoadFromTextFile<Customer>(path, hasHeader: true, separatorChar: ',');
Note that we have specifically defined a Customer class to model a record in the dataset.
Once the data is loaded, it is customary to split it into training and test sets.
1// Split data
2var splitData = ctx.Data.TrainTestSplit(data, testFraction: 0.2);
Transforming data
Contrary to the academic literature, real-world scenarios do not present perfectly formatted data. More often than not, the data is not normalized; it requires standardization and, in brief, needs preparation to be correctly trained. ML.NET streamlines this task by offering various features for data preparation.
In our case, we will specify that certain features are categorical, while others need to be normalized.
1// Split data
2var splitData = ctx.Data.TrainTestSplit(data, testFraction: 0.2);
3
4// Process data
5var categoryTransformer = ctx.Transforms.Categorical.OneHotEncoding(new[]
6{
7 new InputOutputColumnPair("Country", "Country"),
8 new InputOutputColumnPair("Gender", "Gender"),
9 new InputOutputColumnPair("Tenure", "Tenure"),
10 new InputOutputColumnPair("CreditCard", "CreditCard"),
11 new InputOutputColumnPair("ActiveMember", "ActiveMember"),
12});
13var normalizeTransformer = ctx.Transforms.NormalizeMinMax(new[]
14{
15 new InputOutputColumnPair("CreditScore", "CreditScore"),
16 new InputOutputColumnPair("Age", "Age"),
17 new InputOutputColumnPair("Balance", "Balance"),
18 new InputOutputColumnPair("ProductsNumber", "ProductsNumber"),
19 new InputOutputColumnPair("EstimatedSalary", "EstimatedSalary"),
20});
21var featuresTransformer = ctx.Transforms.Concatenate("Features", new[]
22{
23 "CreditScore", "Country", "Gender", "Age", "Tenure", "Balance", "ProductsNumber", "CreditCard", "ActiveMember", "EstimatedSalary"
24});
25
26var dataPipe = categoryTransformer.Append(normalizeTransformer).Append(featuresTransformer);
Defining the operation to be performed
Here, we simply inform ML.NET that we aim to perform binary classification and specify the algorithm we want to use.
Note here that we are using a quasi-Newton method (L-BFGS method).
In the following code, we also attempt to evaluate the accuracy of our model by testing it against the test set.
1dataPipe.Append(ctx.BinaryClassification.Trainers.LbfgsLogisticRegression());
2
3var trainedModel = dataPipe.Fit(splitData.TrainSet);
4
5// Measure trained model performance
6var predictions = trainedModel.Transform(splitData.TestSet);
7
8// Extract model metrics and get accuracy
9var trainedModelMetrics = ctx.BinaryClassification.Evaluate(predictions, labelColumnName: "Label", predictedLabelColumnName: "PredictedLabel");
10var accuracy = trainedModelMetrics.Accuracy;
Making predictions
After the model has been trained, it becomes possible to generate predictions, which is the ultimate goal of machine learning.
1// Predict an unforeseen input
2var X = new Customer()
3{
4 CreditScore = 845,
5 Country = "France",
6 Gender = "Female",
7 Age = 40,
8 Tenure = 5,
9 Balance = 10,
10 ProductsNumber = 1,
11 CreditCard = true,
12 ActiveMember = true,
13 EstimatedSalary = 135000
14};
15
16
17var pe = ctx.Model.CreatePredictionEngine<Customer, CustomerPrediction>(trainedModel);
18var Y = pe.Predict(X);
Final thoughts
In this post, we delved into the intricacies of logistic regression, exploring its mathematical details and understanding how its training can be executed. However, it's crucial to emphasize that logistic regression may not always be the most accurate algorithm for classification tasks. If the data is not linearly separable, it might be necessary to apply a transformation beforehand (using radial basis functions, for example) or consider alternative methods.
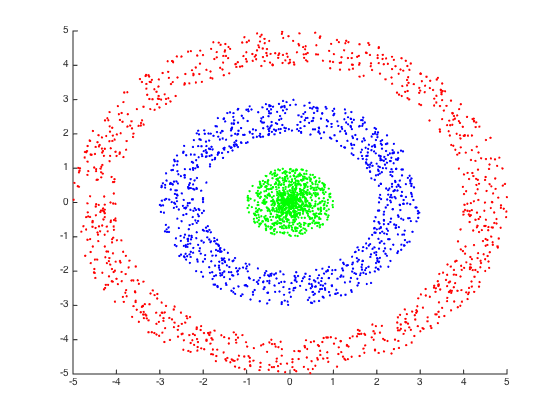
In such a case, the predictions will likely be very poor, necessitating a preliminary transformation.
![]()
This underscores one of the reasons why more sophisticated techniques, such as neural networks or kernel machines, have been developed. We will delve into these advanced methods in an upcoming article.
Please refer to this article for guidance on implementing a neural network in C#.
If you wish to delve deeper into this topic, acquire the following books, which encompass all the concepts emphasized in this series and delve into more advanced ones.
Pattern Recognition and Machine Learning (Bishop)
Machine Learning: An Algorithmic Perspective (Marsland)
Probabilistic Machine Learning: An Introduction (Murphy)
Probabilistic Machine Learning: Advanced Topics (Murphy)
Numerical Optimization (Nocedal, Wright)
Do not hesitate to contact me shoud you require further information.