Writing a simple lexical analyzer for SQL - Part 3
In this article, we elucidate finite automata, a fundamental data structure essential for lexical analysis.
What are finite automata ?
A finite automaton is a computational model with a finite set of states, transitions between these states, and an input alphabet that drives state transitions. It operates in discrete steps, processing input symbols to move between states based on predefined rules.
States are a finite set of distinct conditions or situations that the automaton can be in at any given time.
Transitions are rules or functions that define how the automaton transitions from one state to another in response to input symbols.
The input alphabet is the set of symbols that the automaton reads as input during its operation.
The initial state is the starting point of the automaton's operation, indicating its initial condition.
The accepting states are the states that, when reached, signify the successful recognition or acceptance of an input sequence.
The theory underpinning finite automata is highly intricate and fascinating. While we won't explore profound theoretical concepts here, such as deterministic or nondeterministic automata or the remarkable Kleene's theorem, readers intrigued by these subjects can refer to Introduction to Automata Theory, Languages, and Computation (Hopcroft, Motwani, Ullman) for more comprehensive insights.
The above definition is quite formal, and readers who are not well-versed in these data structures may not find it more accessible. Consequently, we will take a graphical approach to illustrate and make tangible this incredibly useful structure.
A simple worked example
Imagine a situation where we aim to design a data structure for identifying the word SELECT. The subsequent image illustrates the steps to take in this process.
- Commencing from state 1 (depicted in red in the figure above) and utilizing the string "SELECT", we initiate the process. Since the string begins with an 'S', we attempt to transition to a state with an 'S'-labeled transition. As such a transition exists, we progress to state 2.
- Subsequently, encountering the character 'E', we iterate through the process again—transitioning from state 2 to another state with an 'E'-labeled transition.
- This pattern continues until we reach state 7. In our example, state 7 is highlighted in green, indicating an accepting state. This signifies that we can conclude the process here and determine the recognized string, which, in this case, is precisely "SELECT".
Can this structure recognize the word FROM ?
Once more, we initiate the process from state 1 (our initial state). However, this time, we employ the string "FROM". Given that this string commences with an 'F', we endeavor to transition to a state with an 'F'-labeled transition. As no such transition exists, we reach an impasse, and it becomes evident that this structure does not recognize the word FROM.
To rectify this, it is necessary to enhance our structure by introducing the requisite states.
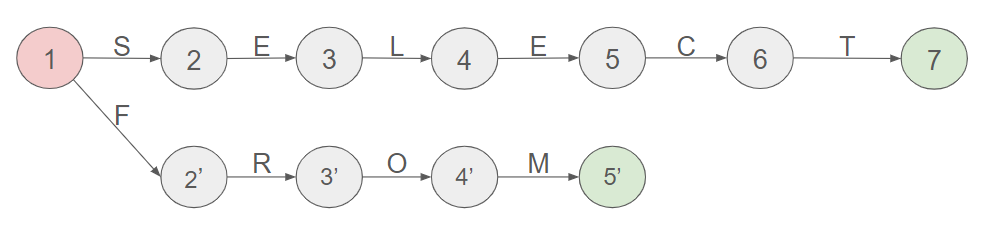
Can this structure recognize the word SEL ?
- Once again, we commence the process from state 1, utilizing the string "SEL". As the string begins with an 'S', we attempt to transition to a state with an 'S'-labeled transition. Since such a transition exists, we proceed further.
- Iterating through the process, we encounter a blockage in state 4 as the string is exhausted. Given that state 4 is not an accepting state, we deduce that this structure does not recognize the word SEL.
And so ?
The structures described above are finite automata:
- States are represented by the set of all circles (1 through 7 in our case).
- Six transitions are labeled with individual characters; transition from one state to another is only possible if there exists a transition labeled with the current character.
- The input alphabet consists of sequence of alphanumeric characters.
- An initial state is designated in red.
- An accepting state is identified in green.
An automaton recognizes a string if and only if, starting from the initial state, it can traverse to one of the accepting states by transitioning through the constituent characters of the string.
On its own, the current data structure serves little practical purpose, as identifying the word SELECT can be accomplished without such intricate machinery. However, envision how this structure can be employed to recognize identifiers.
Recognizing identifiers
For our illustration, let's suppose that identifiers consist solely of sequences of alphabetic characters, with numeric characters not permitted. For instance, "Customers" is considered an identifier, while "state03" is not, as it contains non-alphabetic characters (0 and 3). Additionally, we impose the requirement that an identifier must consist of at least one character.
With this stipulation, the following automaton has the capability to identify an identifier.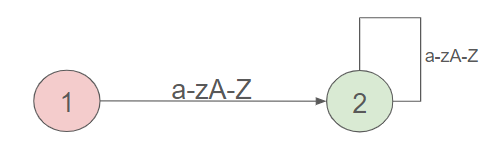
We initiate the process from state 1, employing the string "Customers". As the string commences with a 'C', we endeavor to transition to a state with a 'C'-labeled transition. Successfully finding such a transition, we progress to state 2. Continuing through the process, we can consume all the characters and conclude in an accepting state. We conclude that Customers is recognized as an identifier.
We can observe that there is a transition from a state to itself in this case. Such transitions are permitted by the definition of an automaton.
It is quite noteworthy how the final structure is straightforward in comparison to the task it is designed to perform. With just two states and a handful of transitions, we can now accomplish a process that might appear quite complex without the aid of such a data structure.
It's time to put these concepts into practice, and we will exemplify the aforementioned ideas with a basic lexical analyzer for SQL.
What is SQL ?
SQL stands as a time-honored language employed across all relational databases. In the context of this discussion, we presume that readers possess a proficient understanding of this technology without requiring refreshers. Our aim is to examine strings similar to the examples below.
1SELECT *
2FROM Customers c
3WHERE c.Id = 10100
1SELECT c.Name, c.Age
2FROM Customers c
3WHERE c.Id = 10100 AND c.Age <= 35
1Customers SELECT WHERE Id FROM
1SELECT *
2FROM Customers04
Defining the categories
For illustrative purposes, we will categorize our lexemes into seven distinct categories as outlined in the table below.
| Name | Example |
|---|---|
| KEYWORD | SELECT, FROM, ... |
| OPERATOR | =, <>, LIKE, ... |
| IDENTIFIER | Customers, Id, ... |
| PUNCTUATION | ., !, (, ... |
| NUMBER | 1, 7653, ... |
| LITERAL | 'john', '%michel%', ... |
| ALL | * |
Building the automata
We will need to construct an automaton for each of the categories mentioned above. To illustrate, we will outline the automaton for literals. The others are relatively straightforward and can be found in the source code written in C#.

Starting from state 1, a transition to state 2 is only possible with a ' character. Once in state 2, any number of alphabetic characters is allowed, and eventually, we can transition to state 3 only with another '. If the input string is exhausted, we can conclude that it is a literal. Otherwise, we need to explore another category.
It's sufficient for theory, and now we will proceed to practically implement a SQL lexical analyzer in C#.