Implementing vector databases in C# with kd-trees - Part 6
In this final post, we implement a kd-tree in C# and examine how nearest neighbor searches perform compared to the naive implementation we introduced earlier.
Implementing the IEmbeddingStorer with kd-trees
We have already discussed how to conduct a naive search. Now, we will implement a new class that implements the IEmbeddingStorer interface using kd-trees. Before we proceed, let's explore how to implement a kd-tree in C#.
Following the definition we outlined earlier, we'll begin by introducing a KdTreeNode class, which inherently represents a node within a kd-tree.
1public class KdTreeNode
2{
3 public int SplitIndex { get; set; }
4 public double SplitValue { get; set; }
5 public KdTreeNode Left { get; set; }
6 public KdTreeNode Right { get; set; }
7 public Embedding Embedding { get; set; }
8
9 public KdTreeNode(int splitIndex, double splitValue, Embedding embedding)
10 {
11 SplitIndex = splitIndex;
12 SplitValue = splitValue;
13 Left = null;
14 Right = null;
15 Embedding = embedding;
16 }
17}
Therefore, a kd-tree simply consists of a reference to the root node.
1public class KdTree
2{
3 private KdTreeNode _root;
4 private int _dimensions;
5
6 public KdTree(int dimensions)
7 {
8 _dimensions = dimensions;
9 _root = null;
10 }
11}
Now, we need to add methods for inserting embeddings and performing queries.
1public class KdTree
2{
3 // ...
4
5 public void Insert(Embedding embedding)
6 {
7 _root = Insert(_root, embedding, 0);
8 }
9
10 public List<Embedding> FindNearestNeighbours(IDistance distance, Embedding target, int n)
11 {
12 var bestNodes = new SortedList<double, Embedding>(n + 1);
13 FindNearestNeighbours(distance, _root, target, bestNodes, n);
14 return new List<Embedding>(bestNodes.Values);
15 }
16
17 #region Private Methods
18
19 private KdTreeNode Insert(KdTreeNode node, Embedding embedding, int depth)
20 {
21 var splitIndex = depth % _dimensions;
22 var v = embedding.Records[splitIndex];
23
24 if (node == null)
25 return new KdTreeNode(splitIndex, v, embedding);
26
27 if (v < node.SplitValue)
28 node.Left = Insert(node.Left, embedding, depth + 1);
29 else
30 node.Right = Insert(node.Right, embedding, depth + 1);
31
32 return node;
33 }
34
35 private void FindNearestNeighbours(IDistance d, KdTreeNode node, Embedding target, SortedList<double, Embedding> bestNodes, int n)
36 {
37 if (node == null)
38 return;
39
40 var distance = d.DistanceBetween(node.Embedding, target);
41 if (bestNodes.Count < n)
42 {
43 bestNodes.Add(distance, node.Embedding);
44 }
45 else if (distance < bestNodes.Keys[bestNodes.Count - 1])
46 {
47 bestNodes.RemoveAt(bestNodes.Count - 1);
48 bestNodes.Add(distance, node.Embedding);
49 }
50
51 var cd = node.SplitIndex;
52 var nextNode = target.Records[cd] < node.Embedding.Records[cd] ? node.Left : node.Right;
53 var otherNode = target.Records[cd] < node.Embedding.Records[cd] ? node.Right : node.Left;
54
55 FindNearestNeighbours(d, nextNode, target, bestNodes, n);
56
57 if (bestNodes.Count < n || Math.Abs(node.Embedding.Records[cd] - target.Records[cd]) < bestNodes.Keys[bestNodes.Count - 1])
58 {
59 FindNearestNeighbours(d, otherNode, target, bestNodes, n);
60 }
61 }
62
63 #endregion
64}
We still need to implement the IEmbeddingStorer interface with a class that leverages kd-trees.
1public class KdTreeEmbeddingStorer : IEmbeddingStorer
2{
3 private const int DIMENSION = 6;
4 private KdTrees.KdTree _tree = new KdTrees.KdTree(DIMENSION);
5
6 public void LoadEmbeddings(List<Embedding> embeddings)
7 {
8 foreach (var embedding in embeddings)
9 {
10 _tree.Insert(embedding);
11 }
12 }
13
14 public List<Embedding> FindNearestNeighbours(IDistance distance, Embedding embedding, int n)
15 {
16 return _tree.FindNearestNeighbours(distance, embedding, n);
17 }
18}
Is it truly better than the naive method ?
To answer this question, we will compare the two methods in action using BenchmarkDotNet.
BenchmarkDotNet is a powerful .NET library used for benchmarking our code. It helps us measure and compare the performance of different implementations or code snippets by running them in a controlled environment and providing detailed performance metrics.
The library automates the process of running benchmarks, collecting data, and generating comprehensive reports, making it easier to identify performance bottlenecks and optimize our code.
To do this, create a Console Application project, add the BenchmarkDotNet package, and then include the following code:
1internal class Program
2{
3 static void Main(string[] args)
4 {
5 var summary = BenchmarkRunner.Run(typeof(Program).Assembly);
6 }
7}
8
9public class EmbeddingStorerBenchmark
10{
11 private KdTreeEmbeddingStorer _kdTreeEmbeddingStorer;
12 private ListEmbeddingStorer _listEmbeddingStorer;
13
14 private IDistance _distance;
15
16 private Embedding _query;
17
18 [GlobalSetup]
19 public void Setup()
20 {
21 var path = AppContext.BaseDirectory + "/dataset10000.csv";
22 var lines = File.ReadAllLines(path);
23
24 var embeddings = new List<Embedding>(); var culture = new CultureInfo("en-US");
25 foreach (var line in lines)
26 {
27 var records = line.Split(';').Select(x => Convert.ToDouble(x.Trim(), culture)).ToArray();
28 var embedding = new Embedding(records);
29 embeddings.Add(embedding);
30 }
31
32 _kdTreeEmbeddingStorer = new KdTreeEmbeddingStorer();
33 _listEmbeddingStorer = new ListEmbeddingStorer();
34 _distance = new EuclidianDistance();
35
36 _kdTreeEmbeddingStorer.LoadEmbeddings(embeddings);
37 _listEmbeddingStorer.LoadEmbeddings(embeddings);
38
39 _query = new Embedding(new double[] { 0.25551613824067143, -0.8849031990448337, -0.7598131480221972, 0.50383174460758, -0.4510775673617402, -0.3108595333783353, 0.7336475844915646, 0.263399338913618, 0.6692907911816828, 0.9378379967863208 });
40 }
41
42 [Benchmark]
43 public List<Embedding> FindNeighboursWithList() => _listEmbeddingStorer.FindNearestNeighbours(_distance, _query, 5);
44
45 [Benchmark]
46 public List<Embedding> FindNeighboursWithKdTree() => _kdTreeEmbeddingStorer.FindNearestNeighbours(_distance, _query, 5);
47}
Case 1: Our dataset consists of 10,000 records, each with 10 dimensions.
Our objective is to find the 5 nearest neighbors for a given target.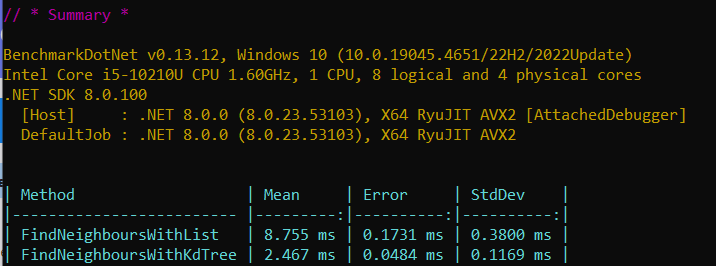
Case 2: Our dataset consists of 100,000 records, each with 10 dimensions.
Our objective is to find the 5 nearest neighbors for a given target.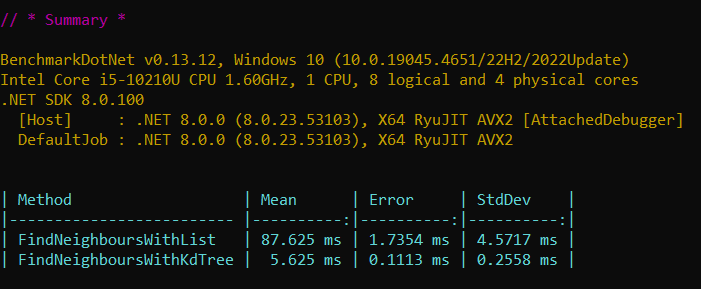
Final thoughts
In this series, our aim was to provide a comprehensible overview of how vector databases can be implemented in their core engine.
If you wish to delve deeper into this topic, acquire the following books, which encompass all the concepts emphasized in this series and delve into more advanced ones.
Foundations of Multidimensional and Metric Data Structures (Samet)
Introduction to Algorithms (Cormen, Leiserson, Rivest, Stein)
Do not hesitate to contact me shoud you require further information.