Implementing vector databases in C# with kd-trees - Part 5
In this post, we explore how nearest neighbor searches can be performed using a kd-tree.
Earlier, we discussed why finding the nearest neighbors of a specific embedding is crucial in certain applications. Our objective now is to demonstrate how this operation can be efficiently achieved using kd-trees.
The approach involves proceeding similarly to a traditional binary tree, where we traverse the entire tree to locate the subspace corresponding to the target. Unlike a classical BST however, the process does not end there, as the closest neighbors may exist in other subtrees. To illustrate our discussion, we will rely on the following example.

First case
We will start with a straightforward scenario where the embedding initially found by traversing the tree is indeed the closest neighbor: imagine that we want to find the nearest neighbor of $(25, 70)$.
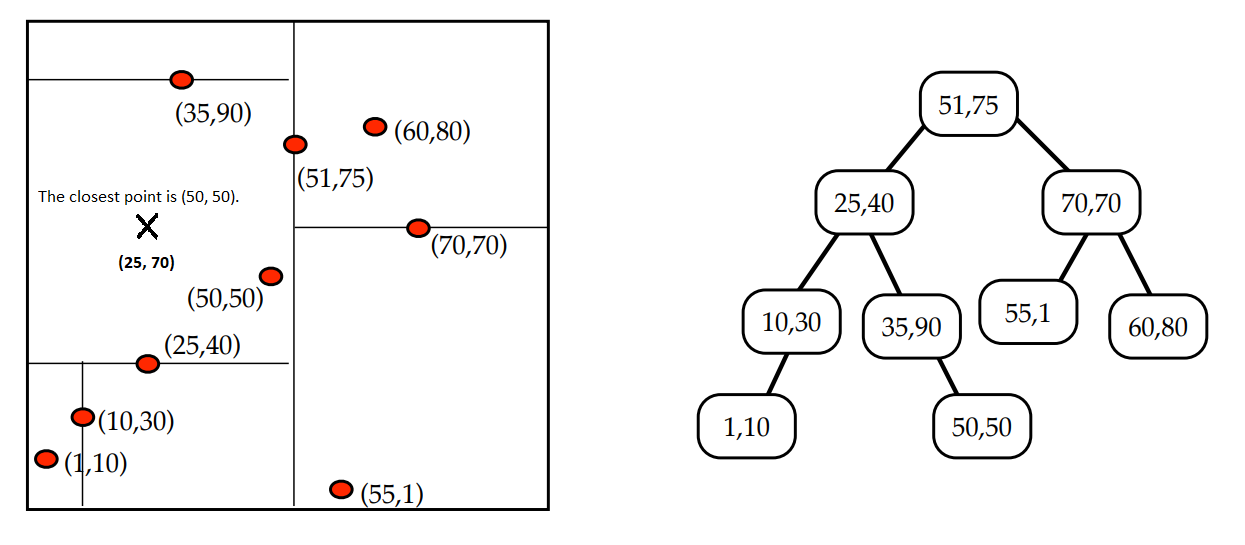
Here, it is not possible for the closest point to exist in other subspaces because the distance to the boundaries (hyperplanes in mathematical terms) is greater than the distance to any point in the subtree.
In mathematical terms, if the orthogonal projection along the current split axis is greater than the orthogonal projection of the target embedding along the same axis, then we can bypass every point in the subtree and move up to the parent level.
Second case
Now, let's consider a more interesting scenario: we want to find the nearest neighbor of $(52,72)$.
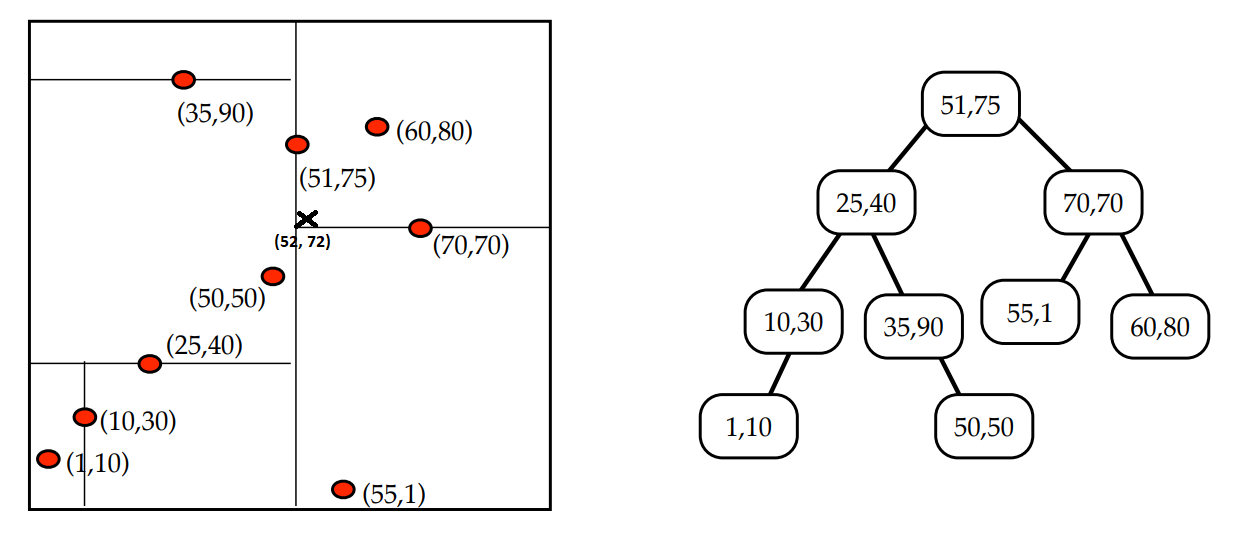
The initial closest embedding found by traversing down the tree is $(60, 80)$, but it's evident that this is not the closest point to our target.
In fact, the distance to the other subtree (the one containing the point $(55, 1)$) is less than the distance to the initially found point $(60, 80)$. Therefore, it is entirely possible that a point in this subspace could be the closest and we need to investigate it. After visiting this subspace, we continue our process towards the root and explore whether a closest embedding may exist in the left subtree of the root. In this particular case, we may end up visiting the entire tree, and thus not gain any performance compared to a naive implementation.
To conduct our searches, we begin from the most likely subspace and traverse up the tree until we reach the root. It's important to note that we must examine all levels and cannot stop prematurely. Our goal is to visit the fewest subtrees possible in the process.
Searching in a kd-tree typically operates with logarithmic time complexity, which makes it highly desirable.
Now that we have a comprehensive understanding of what a kd-tree is and how it can efficiently perform searches for multidimensional data, let's put it into action by implementing it in C#.