Implementing vector databases in C# with kd-trees - Part 3
In this post, we will explore the primary applications of vector databases and the essential requirements they must fulfill to be effective. Additionally, we will provide an initial naive C# implementation.
What are the applications of vector databases ?
As noted in the previous post, vectors fundamentally represent multidimensional data that encapsulates abstract objects.
Consider a scenario where we are storing documents that describe products (for instance, on an e-commerce website) and we have defined an embedding model for representing textual data.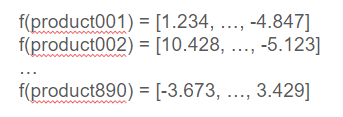
It is evident that the embedding model is crucial and must be meticulously crafted: documents that are closest in "reality" should be close in the vector space to provide meaningful recommendations.
So, how can we conduct efficient searches ?
To make this article less abstract, let's now implement a bit of C# code to explore a very basic implementation of nearest neighbor search. This implementation will serve as a benchmark compared to the more sophisticated data structures we'll explore next.
Firstly, we will define an Embedding class to serve as a simple model for an array of doubles.
1public class Embedding
2{
3 public double[] Records { get; set; }
4
5 public Embedding(double[] records)
6 {
7 Records = records;
8 }
9}
Next, we will define an interface that allows us to store and query embeddings. We will begin by exploring a naive implementation of this interface, followed by a more sophisticated one.
1public interface IEmbeddingStorer
2{
3 void LoadEmbeddings(List<Embedding> embeddings);
4
5 List<Embedding> FindNearestNeighbours(IDistance distance, Embedding embedding, int n);
6}
This interface is straightforward, containing two methods: one for loading a list of initial embeddings, and the other for finding the nearest neighbors of a target embedding.
To complete the implementation, we will also introduce an interface to represent the distance between two embeddings.
1public interface IDistance
2{
3 double DistanceBetween(Embedding e1, Embedding e2);
4
5 double DistanceBetween(double d1, double d2);
6}
A concrete implementation could be the Euclidean distance. It's worth noting that other implementations are possible and depend on the specific application requirements.
1public class EuclidianDistance : IDistance
2{
3 public double DistanceBetween(Embedding e1, Embedding e2)
4 {
5 var dimension = e1.Records.Length; var distance = 0.0;
6 for (var i = 0; i < dimension; i++)
7 {
8 distance = distance + Math.Pow(e1.Records[i]-e2.Records[i], 2);
9 }
10
11 return distance;
12 }
13
14 public double DistanceBetween(double d1, double d2)
15 {
16 return Math.Pow(d1-d2, 2);
17 }
18}
With this groundwork laid out, we can now implement a first naive version of the FindNearestNeighbours method. This straightforward approach involves iterating over all embeddings to find the 5 nearest ones.
1public class ListEmbeddingStorer : IEmbeddingStorer
2{
3 private List<Embedding> _embeddings;
4
5 public void LoadEmbeddings(List<Embedding> embeddings)
6 {
7 _embeddings = embeddings;
8 }
9
10 public List<Embedding> FindNearestNeighbours(IDistance distance, Embedding embedding, int n)
11 {
12 var res = new List<EmbeddingWithDistance>();
13 foreach (var e in _embeddings)
14 {
15 var dist = distance.DistanceBetween(e, embedding);
16 if (res.Count < n) res.Add(new EmbeddingWithDistance(dist, e));
17 else
18 {
19 var max = res.OrderByDescending(i => i.Distance).First();
20 if(dist < max.Distance)
21 {
22 res.Remove(max);
23 res.Add(new EmbeddingWithDistance(dist, e));
24 }
25 }
26 }
27
28 return res.Select(t => t.Embedding).ToList();
29 }
30}
31
32public class EmbeddingWithDistance
33{
34 public double Distance { get; set; }
35
36 public Embedding Embedding { get; set; }
37
38 public EmbeddingWithDistance(double distance, Embedding embedding)
39 {
40 Distance = distance;
41 Embedding = embedding;
42 }
43}
Indeed, this implementation is naive because its time complexity is linear in the number of items: every record must be visited to produce the result. Therefore, it is not scalable beyond small datasets containing only several thousand items.
For more information about time complexity, please refer to the following article.
Modern artificial intelligence applications deal with vast amounts of data, often reaching several hundreds of millions of records. Therefore, relying on linear time search operations is not feasible and it is crucial for vector databases to efficiently find nearest neighbors, or in other words, to perform searches rapidly. Our challenge is to prioritize a data structure designed for efficient multidimensional searching.