Implementing vector databases in C# with kd-trees - Part 2
In this post, we will briefly summarize what vector databases are and why they have gained popularity.
A detailed description of what vector databases are is available on this site.
What are vector databases ?
Vector databases are specialized databases designed to efficiently store and query high-dimensional vector data. Unlike traditional relational databases that are optimized for tabular data, vector databases are tailored to handle vectors as primary data types.
They provide mechanisms for storing, indexing, and querying vectors in a manner that preserves their high-dimensional structure and enables efficient similarity search and other vector-based operations. Examples of vector databases include Milvus, Faiss, and Pinecone.
OK but why do we need to store vectors at all ?
We already have relational databases and other paradigms for storing data. So why bother with these new kinds of databases ?
Well, conventional databases are great for storing traditional data. For instance, an e-commerce website handles transactions and products that can be represented as tabular objects with attributes, making it easy to query this data using simple SQL syntax.

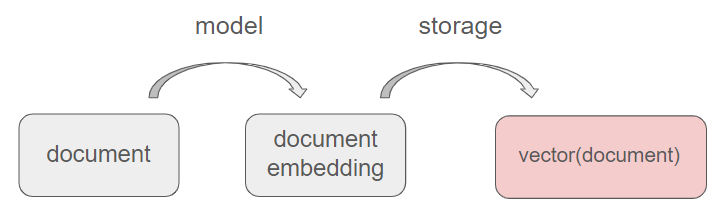
Designing this embedding is more an art than a science and depends on the specific object we want to represent (for example, documents can be modeled using the TF-IDF paradigm). Ultimately, embedding constitutes the real value added and is likely the most challenging aspect to achieve in an artificial intelligence application.
Once data is stored in a vector space, everything becomes simpler: it is easy to find similar objects by computing the similarity between two vectors, and it is easy to perform arithmetic operations on objects. For example, we can subtract one document vector from another and explore the resulting document vector.
But how to store all these vectors ?
Now that we grasp the importance of vectors, a natural question arises: how can we efficiently store and query these vectors ? We could certainly utilize existing platforms such as relational or NoSQL databases, but we will soon find that their underlying foundations are not well-suited for this purpose. Why ? Because vectors are inherently multidimensional data, and conventional databases lack native data structures capable of manipulating them.
Vector databases are databases explicitly engineered to efficiently store and query vectors (which serve as mathematical representations of abstract objects such as documents or images).
The remainder of this series aims to explore potential data structures suited for this purpose, observe them in action, and implement simplified versions to understand how they can be enhanced.