Implementing the Google's autocomplete feature with ngram language models - Part 2
In this post, we provide a brief overview of the Google's autocomplete feature to showcase a concrete application of the concepts we are exploring.
What is the Google's autocomplete feature ?
Everyone is accustomed to making searches on the Google search engine. As we start typing, Google attempts to automatically complete our queries by suggesting possible sentence completions. This feature saves time, minimizes typing effort, and helps users refine their queries by providing relevant suggestions based on popular searches and contextual understanding.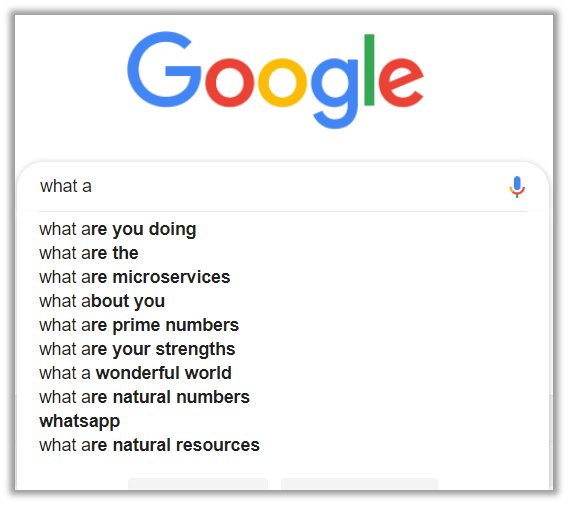
This functionality is known as the Google's autocomplete feature and the system generates a list of suggestions based on several factors.
Suggestions are often drawn from commonly searched phrases or queries that match the initial input.
It considers the context of the input, including current trends, location, and the user's search history (if enabled).
It employs advanced algorithms, including machine learning techniques like language models, to analyze patterns in search behavior and predict user intent.
By providing these suggestions, the feature saves time, reduces effort in typing, and often refines the query for more relevant results.
At its core, the autocomplete functionality is powered by a combination of algorithms, data analysis, and user-centric design, making it an integral part of modern search experiences. On our part, we will use only a very simple technique (known as the n-gram language model) and see it in action.
This technique requires however an understanding of basic probability concepts. That's why, before delving into a deeper explanation, we will first focus on probability theory in the next post.
Implementing the Google's autocomplete feature with ngram language models - Part 3