Understanding CQRS architecture - Part 5
In this concluding post, we will explore how CQRS is conventionally exposed and introduce intricate concepts associated with it.
Running commands and queries in separate databases
As mentioned in the previous post, this aspect is entirely optional but is frequently presented in this manner in blogs and training sessions. It can indeed be beneficial to segregate the two models into separate datastores, especially if one of them experiences high demand while the other is infrequently accessed.
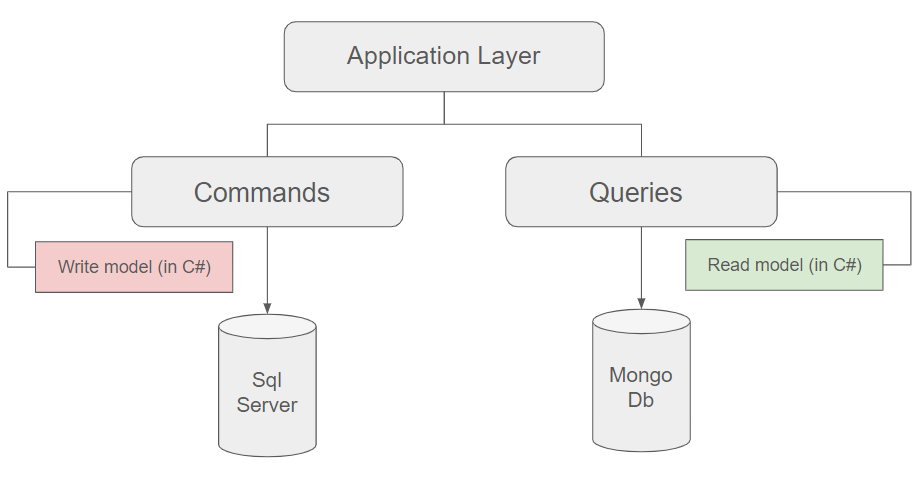
In the figure above, one can observe, for instance, that queries are executed in a document-oriented database such as MongoDB, while commands are carried out against a relational database like SQL Server.
Certainly, an immediate question arises: how is synchronization maintained between the two datastores ?
Synchronizing datastores
The allure of segregating databases lies in harnessing the advantages of both worlds: a database optimized for robust write operations for commands and another tailored for efficient read-intensive tasks for queries. However, in this architectural setup, challenges arise concerning the synchronization of the two datastores. How to do that ?
Using the Saga pattern for distributed transactions
Upon the execution of a command in the write model, a creation or update is committed in the write database, and it will subsequently reflect these changes. However, it is entirely feasible to concurrently execute the same operation in the read database. To guarantee consistency, the implementation of the Saga pattern becomes imperative. For more detailed information, please refer to the article below.
Implementing the Saga pattern on Azure
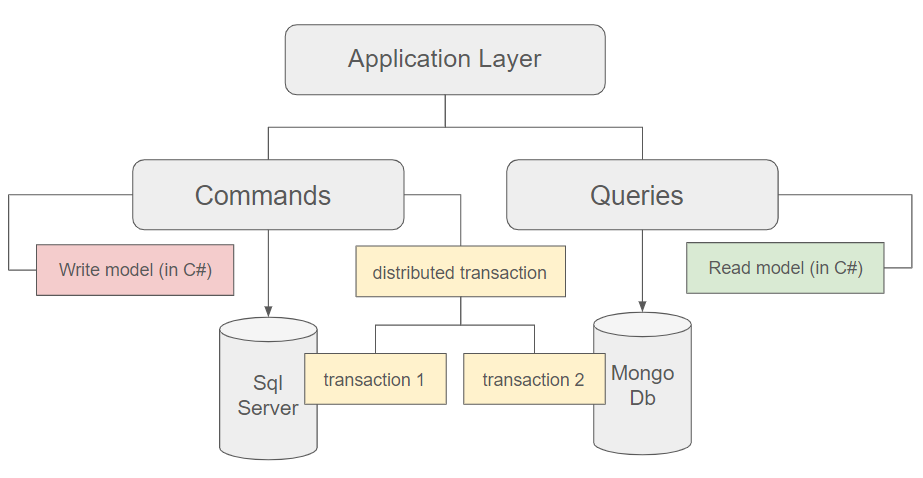
The Saga pattern is a design pattern used in distributed systems to manage long-lived transactions and maintain consistency across multiple services or components.
In a distributed environment, where transactions may span multiple services or databases, achieving and maintaining consistency is indeed challenging. The Saga pattern addresses this challenge by breaking down a long-lived transaction into a series of smaller, self-contained transactions, each representing a step in the overall process. Each step in the saga is a transaction that can be independently executed and, if needed, compensated in case of failure.
Ensuring eventual consistency through asynchronous messaging
The aforementioned design may not be suitable for certain scenarios, especially in cases of extremely high write and read intensities. The risk of contention is notably elevated since each update to the write database triggers a modification in the read database. This concurrent operation can introduce delays and consequently impede the efficiency of the write model.
In situations where performance is paramount, opting for asynchronous messaging proves more advantageous. For instance, using an Azure queue for straightforward cases or Azure Event Hubs for more demanding scenarios allows for improved efficiency. In this approach, the command updates its database and dispatches an event to a queue, triggering an operation in the read database asynchronously.
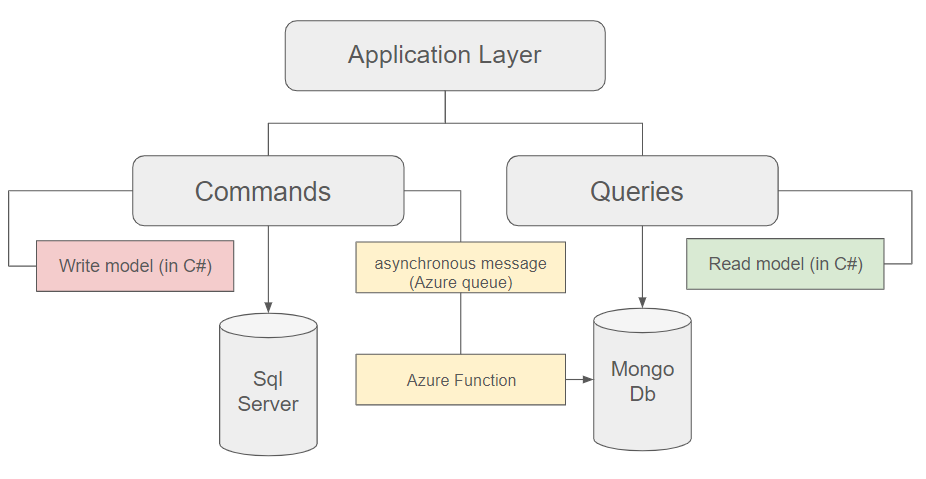
We have to acknowledge here the possibility of temporary inconsistency and that the two datastores might temporarily diverge. This phenomenon is referred as eventual consistency: the system is designed to reconcile these differences over time, ensuring that, eventually, all replicas will converge to a consistent state.
The truth is many kinds of systems will have eventual consistency problems; wherever there is a delay between an input being received, being recorded, and being called out again. These delays are in the order of milliseconds, within the tolerance of most systems. When implementing CQRS, eventual consistency is no more of a concern than it is when using other patterns.
Event Store (https://www.eventstore.com/cqrs-pattern)
Using an event store
A crucial variation of CQRS is the utilization of an event store for the write database.
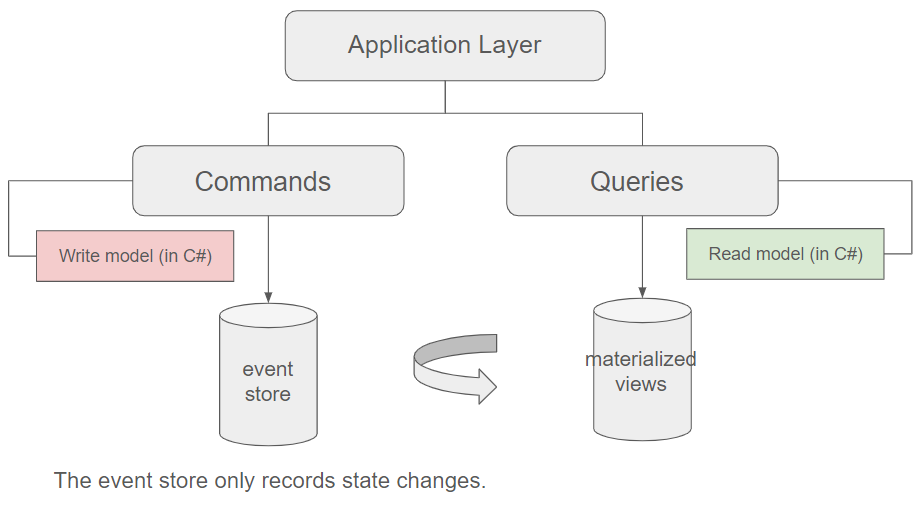
An event store is a specialized database or storage system that is designed to store and manage events as the primary form of data. In this context, events represent notable occurrences or state changes within a system: rather than storing the current state of an entity (like previously with Sql Server), an event store focuses on recording the sequence of events that led to the current state. By replaying the events in sequence, the application's state can be reconstructed at any point in time.
Event stores are commonly implemented using databases optimized for append-only operations to efficiently handle the continuous recording of events. For instance, Azure Storage's append blobs can be considered suitable candidates.
However, a practical issue emerges: recalculating the current system state from events for every query can incur significant computational costs. Hence, it is common practice to capture snapshots of the system state, representing identifiable points in time, to which the most recent events can be subsequently appended. In the figure above, we've labeled these snapshots as materialized views. However, it's important to highlight that materialized views represent just one option among several for optimizing queries.
The arrow shown in the diagram plays a concrete role in implementing these snapshots or materialized views. This implementation can be carried out using tools such as Azure Functions or other serverless computing solutions.
Materialized views are precomputed, stored snapshots or summaries of data from one or more source tables in a database. Unlike regular (non-materialized) views, which are virtual and dynamically generated based on queries, materialized views are physical copies of the data. They serve as a means to improve query performance by reducing the need for complex computations or aggregations at runtime.
This architecture is particularly well-suited for performance-critical scenarios, as appending events to a dedicated store is typically a rapid operation even if it introduces trade-offs, such as increased storage requirements and the need to manage the synchronization of the materialized views with the underlying data.
Final thoughts
If you wish to delve deeper into this topic, acquire the following books, which encompass all the concepts emphasized in this series and delve into more advanced ones.
Domain-Driven Design: Tackling Complexity in the Heart of Software (Evans)
Clean Architecture: A Craftsman's Guide to Software Structure and Design (Martin)
Do not hesitate to contact me shoud you require further information.