How to implement a serverless architecture on Azure - Part 6
In this section, we assess what we've just coded, focusing on certain technical challenges inherent in serverless technologies.
Software design involves a balance between maintainability, cost, execution speed, and performance, and the chosen architecture should address these dilemmas. Can serverless microservices effectively manage this ? Certainly, there is no definitive answer to that question, and in this discussion, we will attempt to evaluate some key aspects.
What about maintainability ?
Maintainability is a key principle for microservices, whether they are serverless or not. It allows for a clear separation of each bounded context, preventing them from becoming intertwined with one another. Some purists are concerned about duplication, as each bounded context may sometimes redundantly redefine access to the same data (for instance, having "GetAllBooks" defined in multiple bounded contexts). But duplication is not a significantly critical phenomenon in itself. What holds significance is the existence of a single point where data can be written into a datastore for a given bounded context.
What about cost ?
Cost-effectiveness is where serverless microservices excel in the early stages of startup development. Azure Functions operate on a pay-as-you-go model, meaning we only pay for the number of executions: in extreme cases, we might not spend any money at all if functions are never triggered. The cost dynamics are different for traditional microservices using Kubernetes and containers, where we need to provision servers from the outset, which can incur significant costs.
What about execution speed ?
This point deserves to be balanced. While in theory, it might be ideal for each bounded context to have its own database (as we previously exposed), in practice, this can be challenging due to the costs involved and the complexity of management. If everyone starts using their own technology, it can lead to a chaotic situation.
Consider an extreme case where there are only 5 bounded contexts, each using a different technology.
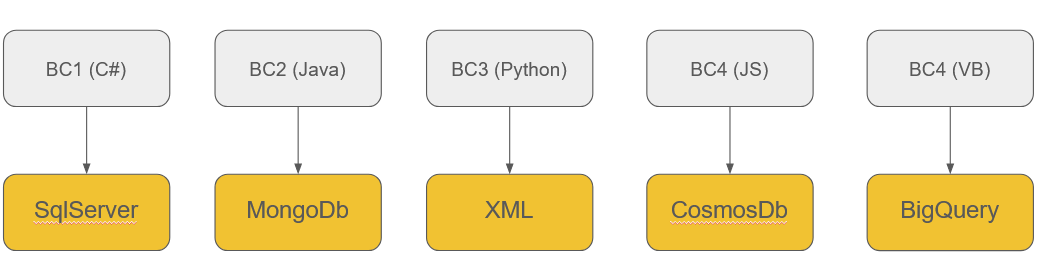
Each project can progress at its own pace, and thus, we are not consistently awaiting the delivery of code from various developers.
But while the project is highly modularized, if, for instance, the Python developer resigns and leaves the project, finding a quick replacement could be challenging, potentially impacting the speed of execution.
Each technology and database requires specialized knowledge. If we use a diverse set of technologies across projects, it may become challenging to find developers with expertise in all areas. This can result in a situation where knowledge is spread thin, and it becomes harder to maintain and enhance different parts of your system (expertise spread thin).
Integrating systems that use different technologies and databases can be complex. Ensuring seamless communication and data exchange between components becomes more challenging when they are built with diverse technologies.
Developers working on different projects may need to learn and adapt to various technologies and databases, increasing the learning curve and potentially slowing down development.
Maintaining consistency and adhering to coding standards becomes more difficult when different technologies are used. This can result in varying levels of quality and hinder the ability to establish standardized practices across the organization.
A more rational approach could involve using one or two technologies or languages and even sharing databases among different bounded contexts. In this scenario, developers must adhere to a strict discipline to avoid intertwining with their neighbors, although it's not impossible. By following this approach, the departure of an engineer becomes less of a threat.
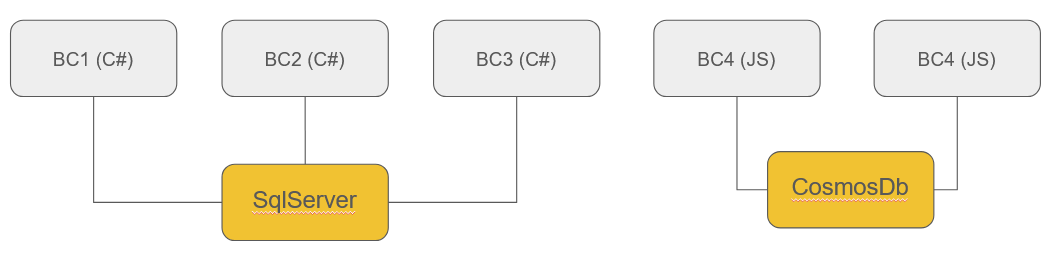
Purists may argue that this approach remains relatively integrated, especially when we rely on a single database. However, we aimed to strike a balance between modularity, ease of maintenance, and cost considerations. While it is certainly possible to employ a dedicated datastore for each bounded context using Docker containers and Kubernetes orchestrators, the question arises: can most startups realistically afford such complex architectures in their initial stages ?
What about performance ? What is "cold start" ?
In the context serverless computing platforms, a "cold start" refers to the initial execution of a function instance after it has been idle or is triggered for the first time. When a function is not actively processing requests, the hosting environment may scale down to conserve resources, leading to a state where no instances of the function are readily available. For instance, Azure Functions resources can be recycled after approximately 15 minutes.
When a new request comes in or an event triggers the function, the hosting environment needs to start a new instance to handle the workload. This process of starting a new instance from a dormant state is known as a "cold start." Cold starts typically take longer to execute than subsequent invocations, where the function instances are warm and readily available. On the contrary, cold start is not a concern for non-serverless architectures because, in theory, there are always active instances, and thus, requests are instantly satisfied.

The duration of a cold start can vary depending on factors such as the programming language, the size of the function's code and dependencies, and the underlying infrastructure. Cold starts are a consideration for serverless applications, especially those with latency-sensitive requirements, as they can introduce additional latency for the first request or event after a period of inactivity.
In the absence of a cold start, the request is processed instantly, as the hosting environment does not need to load and compile resources.
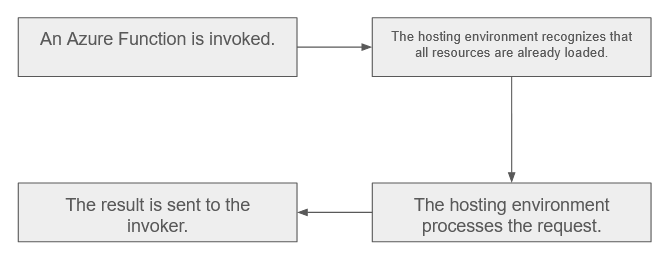
Moral of the story: if optimal performance is crucial, serverless architectures might not be the best choice. However, if the end user is willing to tolerate a brief delay during the first request (typically just a few seconds in practice), these technologies can be a significant game-changer for a company.
In the final part of this series, we will briefly address the deployment process and wrap up the loop.