Implementing a simple garbage collector in C# - Part 2
In this article, it is time to precisely outline the scope of our study and introduce key definitions that will be extensively utilized throughout this series.
Disclaimer: The definitions provided here are our own and are not at all official. We aim to offer interpretations that align with the context. Don't be concerned if some concepts don't precisely align with your usual understanding.
What is garbage collection exactly ?
As said in the introduction, garbage collection is a process in computer programming and memory management where the system automatically identifies and frees up memory that is no longer in use by the program.
Key concepts of garbage collection
Garbage collection automates the process of deallocating memory, eliminating the need for manual memory management by programmers. This helps prevent common issues such as memory leaks and dangling pointers (see below).
Objects are considered reachable if they are directly or indirectly referenced by the program. Garbage collection identifies and marks the objects that are no longer reachable, making them eligible for removal.
The garbage collector identifies and releases memory occupied by unreferenced objects, returning it to the pool of available memory for future use.
Garbage collection can be triggered by various events, such as when the system is running low on memory or when a specific threshold of allocated memory is reached.
Garbage collection is universally adopted by nearly all modern programming languages:
- Java utilizes the JVM's garbage collector, which includes various algorithms such as the generational garbage collector (G1 GC).
- .NET (C#) implements a garbage collector that uses a generational approach.
Garbage collection contributes to the overall robustness and reliability of programs by automating memory management and reducing the likelihood of memory-related errors.
What is the problem with manual (explicit) memory management ?
Manual memory management is not inherently problematic and is still employed in certain prominent programming languages such as C++. However, many are familiar with instances of critical bugs attributable to memory leaks. This is why, relatively early in the history of computer science (with the first technique dating back to the 1950s), methods for automatically managing memory were studied.
Manual memory management indeed introduces several challenges and potential issues:
Failure to deallocate memory properly can lead to memory leaks. Memory leaks occur when a program allocates memory but fails to release it, resulting in a gradual depletion of available memory over time.
Improper handling of pointers can result in dangling pointers, pointing to memory locations that have been deallocated. Accessing such pointers can lead to undefined behavior and application crashes.
Incorrect manipulation of memory, such as writing beyond the bounds of allocated memory, can cause memory corruption. Memory corruption can result in unexpected behavior, crashes, or security vulnerabilities.
Manual memory management increases code complexity, making programs more prone to bugs and harder to maintain. Developers need to carefully track and manage memory allocations and deallocations throughout the codebase.
Manual memory management can contribute to memory fragmentation, where free memory is scattered in small, non-contiguous blocks. This fragmentation can lead to inefficient memory utilization over time.
Mismatched allocation and deallocation operations can occur, leading to errors like double frees or memory leaks. These errors are challenging to identify and debug.
Explicit memory management can require additional code for allocation and deallocation, impacting program performance. Memory allocation and deallocation operations may become bottlenecks in performance-critical applications.
Manual memory management lacks safety features present in automatic memory management systems. Developers need to carefully handle memory-related operations, making programs more error-prone.
Automatic memory management addresses these issues by automating the process of memory allocation and deallocation, reducing the burden on developers and minimizing the likelihood of memory-related errors.
A more comprehensive overview of the benefits of garbage collection and drawbacks of explicit memory management is provided in The Garbage Collector Handbook.
What are stacks, heaps and more ?
When discussing garbage collection, terms such as stack and heap are frequently mentioned to the extent that it may create the impression that they are inherent data structures embedded in the operating system, and thus, must be universally adopted without question. However, the reality is that heap and stacks are just implementation details. In this section, our aim is to elucidate and clarify all these concepts.
In the beginning was the Word.
A program is essentially a text comprising instructions that a computer needs to comprehend. The responsibility of the compiler is to undertake the translation of these high-level instructions into executable code.
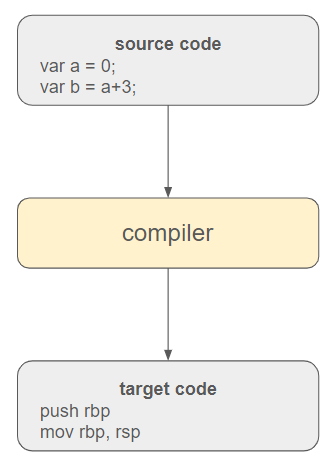
In contemporary programming languages, a virtual execution engine is often interposed between the source code and the operating system. Additionally, the source code is initially translated into an intermediate language to enhance portability and adaptability to different environments.
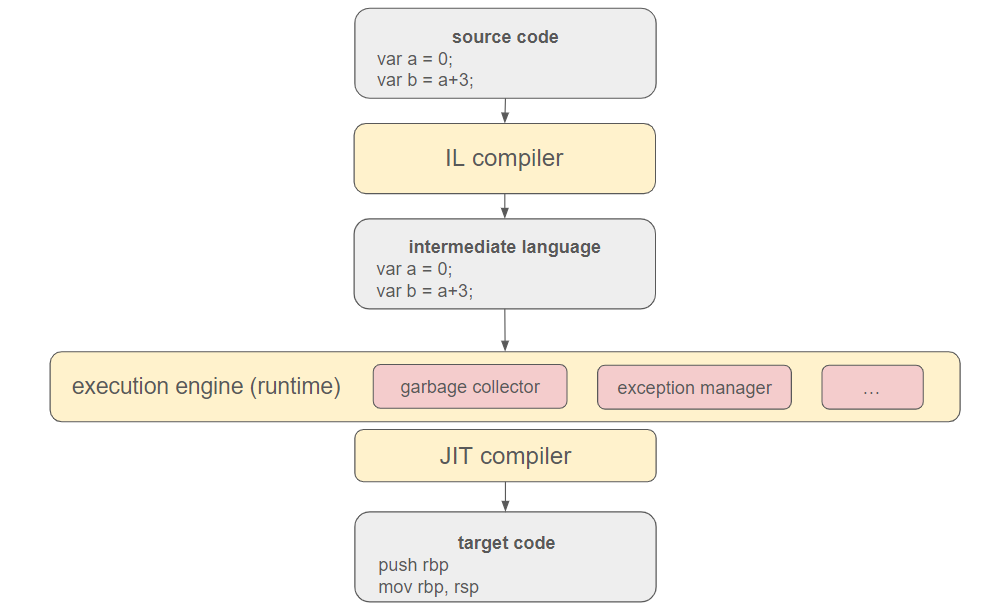
This execution engine encompasses the garbage collector and other techniques (like typechecking, exception management, etc...) to manage the program. The ultimate translation into target code is executed by the just-in-time (JIT) compiler.
Focus on the garbage collector
Certainly, the garbage collector stands out as one of the most crucial components of the execution engine. In this context, our focus will be on describing how memory is organized to facilitate effective management.
A program becomes valuable only when it generates a result, and inevitably, it needs to declare variables and allocate memory to store information at some point.
- The execution engine can anticipate the space it requires in advance, such as when dealing with simple types like integers. Conversely, certain data types, including custom classes or built-in types like strings or arrays of objects, do not allow for such straightforward inference.
- The compiler might only ascertain at runtime the specific location to store variables and reserve memory at that moment (dynamic allocation). If the compiler can determine the variable's lifetime, especially if it is local to a procedure, it becomes simpler to understand when the variable will no longer be necessary (i.e., when deallocation can occur). Conversely, data may persist beyond the call to a function or subroutine and endure indefinitely.
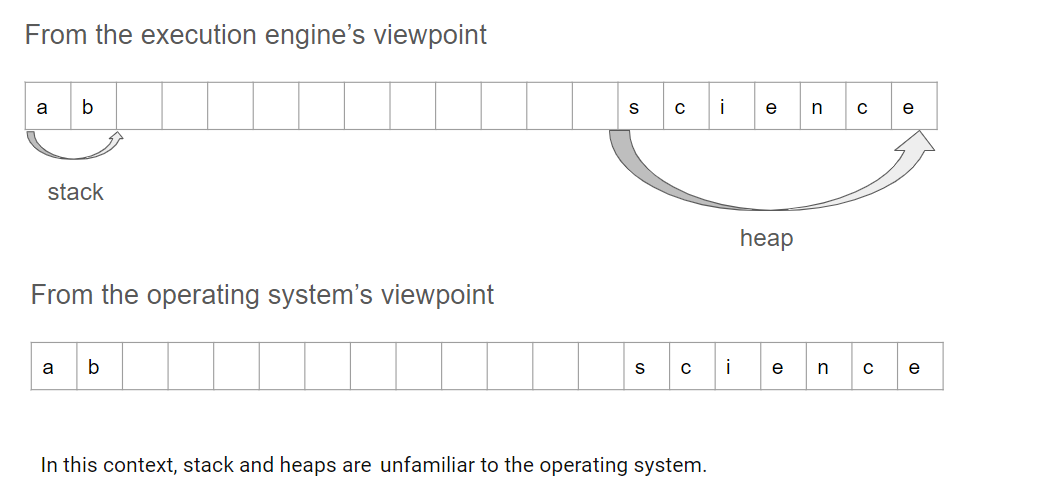
The disparity between a variable's lifetime and the space known in advance to be required necessitates the distinction between two memory areas. Although this differentiation is not obligatory, it has become universally accepted and implemented. A programming language that chooses not to adopt this abstraction may face the risk of fading into obsolescence, but it's essential to acknowledge that alternative schemes are conceivable. Moreover, it's crucial to note that this perspective is solely valid within the context of the execution engine. From the operating system's standpoint, everything eventually boils down to memory chunks allocated somewhere.
Conclusion
When the execution engine can anticipate the lifetime of a variable and infer the required space, it allocates it in a memory area internally referred to as the stack.
In other cases, where the lifetime cannot be definitively decided or the required space is unclear, the execution engine allocates variables in memory areas referred to as the heap.
Disclaimer: This depiction provides only a basic overview of what stacks and heaps are in various programming languages, and purists may find it oversimplified. It is by no means an official definition, as there could be various implementations and interpretations of these abstractions. The key takeaway is the necessity to delineate two memory areas at the execution engine level to facilitate efficient memory management.
How is this series organized, and what approach will we take in our progression ?
Our objective is to model the execution engine in C# with a specific emphasis on the garbage collector. To achieve this, we will need to abstract certain concepts such as the execution engine, the heap, the stack, and the compiler. This is the focus of the next article.