Data modeling in Azure CosmosDb - Part 4
In this concluding article, we put into action the principles and techniques we discussed earlier within the context of our illustrative ecommerce example.
The principles presented here represent a personal interpretation and should by no means be regarded as rigid guidelines to be followed unquestioningly.
What queries should be considered ?
Here, we are applying one of the fundamental principles of the NoSQL paradigm: prioritize consideration of user queries over storage or integrity concerns, as is the case with relational databases. In this context, we can envisage the following inquiries:
- Give me the orders for a specific date
- Give me data about a specific customer
- Give me the orders for a specific customer (customer's history)
- Display the products for a specific category
- Display all the orders by country
- Give me all the customers by country
- ...
It's worth noting at this point that these queries cater to different audiences. Retrieving a customer's history, for instance, holds significant importance for an individual customer (e.g., John Doe) but might not be of paramount concern for those managing the site. The latter group is more focused on obtaining global information, such as retrieving ALL customers by country or ALL orders by date. While customer service may occasionally need such requests, they are less frequent. We will revisit and delve deeper into these considerations when addressing the methods to distinguish and clearly separate various concepts in Azure Cosmos DB.
Choosing accurate partition keys
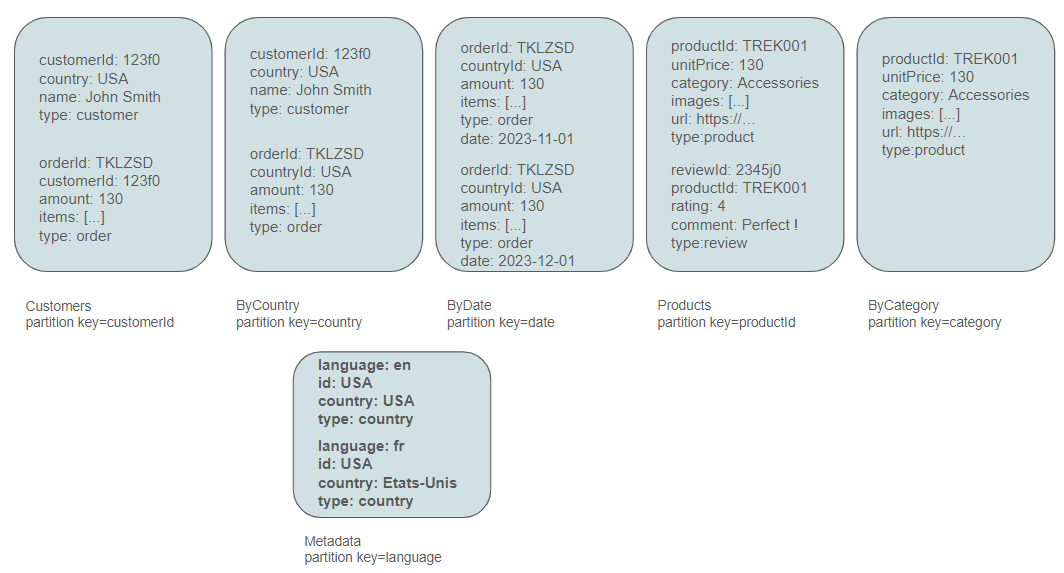
Modeling Customers
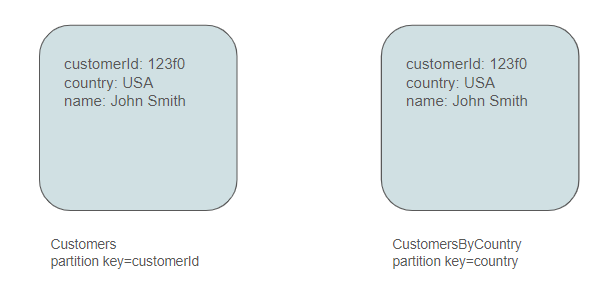
A logical choice for a partition key here, aligning with the mentioned queries, is the customer id. Therefore, it is necessary to establish a container named "Customers" with this customer id as the partition key.

1SELECT *
2FROM Customers c
3WHERE c.customerId = '123f0' and c.id = '123f0'
This SQL query will be highly efficient as it only involves accessing a single document within a specific partition.
At this juncture, we may also consider the requirement to query customers by country. Consequently, it appears logical to introduce a container named CustomersByCountry partioned by country.
1SELECT *
2FROM CustomersByCountry c
3WHERE c.country = 'Russia'
Once again, this SQL query will be efficient. However, we are beginning to address the challenge of having two separate locations where a customer entity is defined. What happens, for instance, if John Smith changes his name ? In such a scenario, we would be compelled to visit all the relevant containers and update each one with the new value. This process could potentially be costly. Here, we need to consider the nature of the application and strike a compromise: is a name change a frequent operation ? Or can we tolerate occasional, albeit more time-consuming, updates in exchange for faster queries ? While the decision ultimately depends on the specific use cases, common sense suggests opting to duplicate data in different containers and accepting occasional, albeit costly, operations.
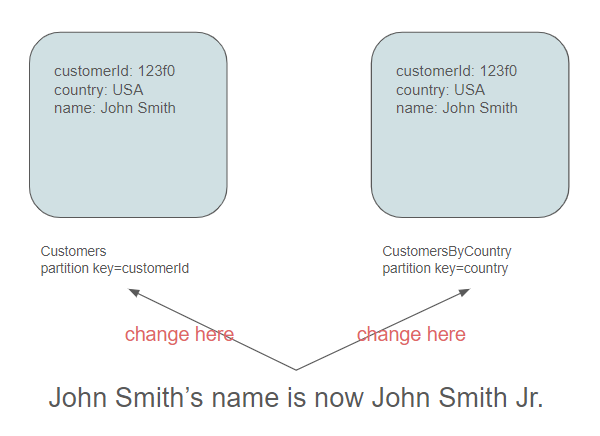
In the NoSQL paradigm, it's common to have data replicated across multiple locations, whereas in the SQL landscape, data integrity is maintained through normalization. Essentially, we trade off the ease of queries (reads) against the complexity of storage (writes). The responsibility to normalize or denormalize falls upon the architecture team.
Modeling Orders
We aim to display orders for a specific customer or orders by country. Fortunately, we have already established the relevant partitioned containers for this purpose.
First approach
In the initial approach, we will include orders in the Customers container, introducing a type attribute to differentiate between customers and orders.
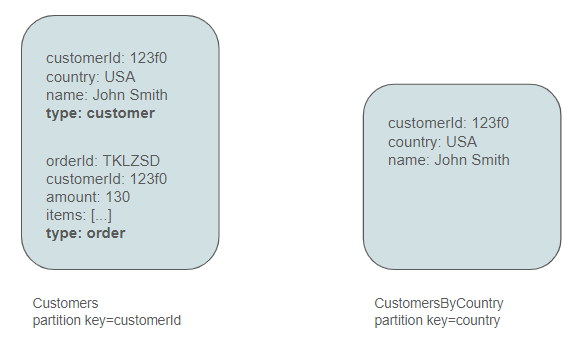
Consequently, we need to adjust our queries to accommodate this modification.
1-- Retrieve a customer
2SELECT *
3FROM Customers c
4WHERE c.customerId = '123f0' and c.id = '123f0' and c.type = 'customer'
1-- Retrieve customer's history
2SELECT *
3FROM Customers c
4WHERE c.customerId = '123f0' and c.type = 'order'
Recall that Cosmos DB is a schemaless database, and thus it allows us to store diverse types of data in the same container.
Second approach
Another approach involves directly incorporating orders that a customer placed into the customer entity.
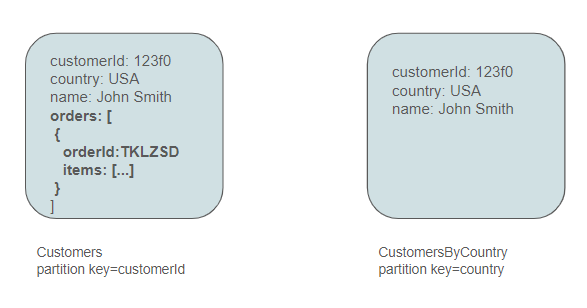
Which approach should we prioritize ? As usual, there is no definitive answer to this question, and we'll need to weigh the pros and cons of each approach.
Pros of the first approach
- The customer entity maintains a consistent size throughout its lifecycle and remains uncluttered by another concept.
- This approach allows a customer to have thousands of orders without jeopardizing the overall schema.
Pros of the second approach
- Querying a customer along with their history doesn't require two separate requests (one for the customer and another for the orders). Everything is contained in a single item. If the application anticipates that a customer will typically have only a few orders, this approach can be a suitable choice.
Everything hinges on our specific needs and the requirements of the application in question. It is the responsibility of developers and architects to have a clear vision of these considerations from the outset.
Likewise, we include the order entity in the CustomersByCountry container.

1SELECT sum(c.amount)
2FROM CustomersByCountry c
3WHERE c.country = 'Russia' and c.type = 'order'
This SQL query will be efficient.
However, it's worth noting a discrepancy in the container name. While named CustomersByCountry, it contains both customers and orders, and potentially other entities in the future. It would be preferable to modify the container name to a more generic and inclusive one.
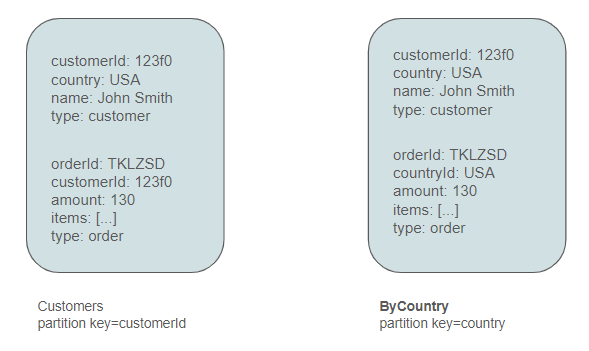
Additionally, we have the requirement to query orders by date, particularly to determine the turnover within a specific date range. Consequently, we must introduce another container named ByDate and partition it based on date.
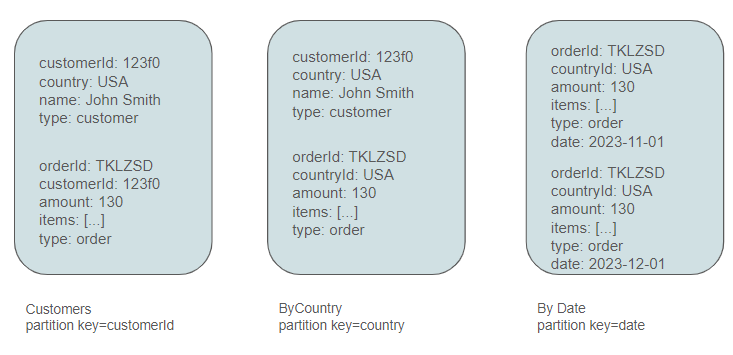
Modeling Products
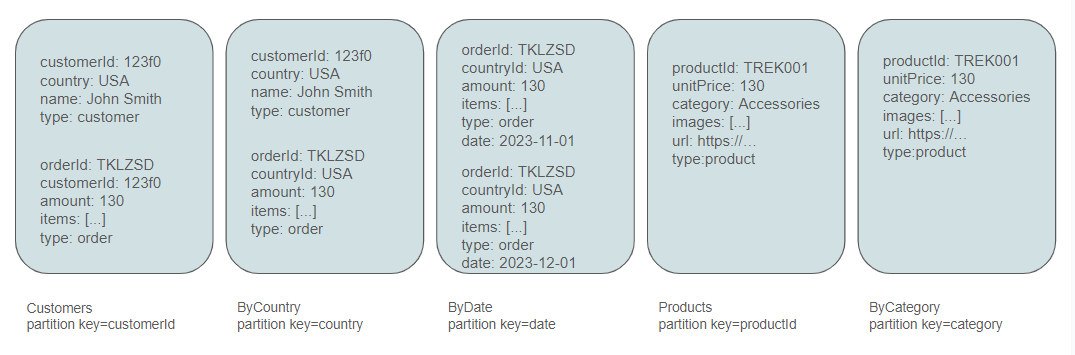
Products are typically queried either by ID, as is common on a product page of an ecommerce website, or by category when navigating a category page. These considerations prompt the creation of two additional containers.
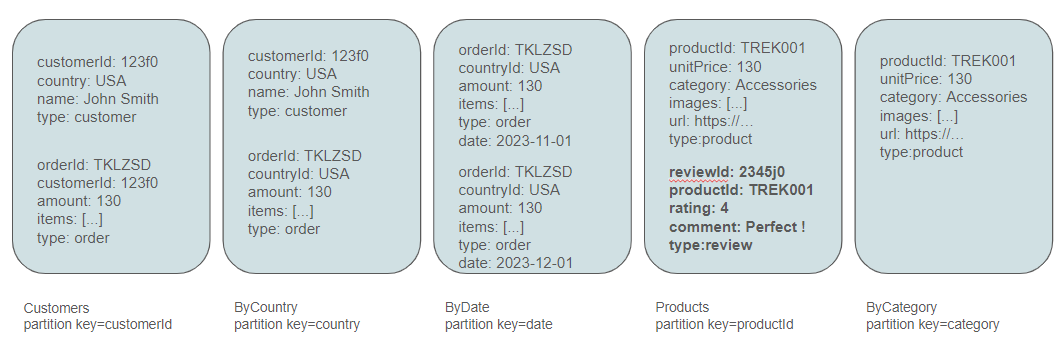
Modeling Reviews
Reviews are frequently queried by product ID, especially when users visit a product page to view ratings provided by customers. Therefore, it seems natural to place reviews in the Products container. The decision to also include them in the Customers container depends on the specific application requirements. In our case, considering that John Smith's overall opinion is deemed unimportant, it's decided not to add a review type in the customer container.
1-- Retrieve all the reviews for a specific product
2SELECT *
3FROM Products c
4WHERE c.productId = 'TREK001' and c.type = 'review'
Incorporating the customer's name directly into the review can eliminate the need for a lookup in the Customers container to retrieve this information. However, it's essential to note that if the customer's name changes, it would require scanning the entire container to update this information. Once again, this decision represents a trade-off between read efficiency and potential update complexity.
If the operation of changing names becomes frequent with unacceptable update costs, an alternative solution could be to create a dedicated inverted index. This involves adding a review entity (type=review) in the Customers container that maintains a list of reviews placed by each customer. Consequently, if a customer changes their name, the application can retrieve the relevant reviews from the Customers container and update only the returned reviews. It's important to note that while this approach addresses update costs, it significantly increases the complexity of the application.
Modeling Countries, Currencies, etc...
Reference data is typically modeled in a single container, partitioned, for instance, by language, and includes a type indicator for metadata.
1-- Retrieve all the countries for the Italian site
2SELECT *
3FROM Metadata c
4WHERE c.language = 'it' and c.type = 'country'
What benefits have we acquired ?
It is crucial to recognize that the transition to a NoSQL paradigm doesn't imply a prior state of a SQL landscape where everything was problematic and nightmarish, and the new technology miraculously makes everything perfect. The suitability of shifting to a NoSQL paradigm depends entirely on our specific requirements, and sometimes, it may not be the optimal decision. Therefore, it's essential to evaluate not only what we have gained but also what we might have lost in the process.
- Theoretically, the new design is infinitely scalable, alleviating concerns about server quotas or limitations (a challenge that can be more cumbersome in SQL).
- The various queries we need to perform are expected to be efficient, as the design has been optimized for such operations.
However, two noteworthy points require specific attention.
- The transactional aspect inherent in the SQL paradigm has been partially compromised. Although CosmosDB does support transactions, there are significant limitations—they must be confined to the same container and can only encompass 100 operations. Consequently, we may need to implement our own mechanisms, such as sagas, introducing considerable complexity to the design.
- While read performance may be enhanced, it comes at the expense of intricate write operations, potentially affecting the consistency of the database in certain situations.
Organizing containers
As mentioned earlier, distinct queries cater to distinct user groups. The Customers container, for instance, will primarily serve the transactional store, utilized by end users of the site to collect personal information. On the other hand, containers like ByDate or ByCountry may be leveraged by data scientists or administrators, specifically those in the back office of the site. These containers facilitate the generation of insightful reports for management, covering metrics such as the number of orders in the last week or month, customer distribution by country, and so forth. From this standpoint, a clear separation of these processes could prove beneficial. Notably, CosmosDB introduces the concept of a database, allowing the grouping of related containers, which aligns well with this organizational strategy.
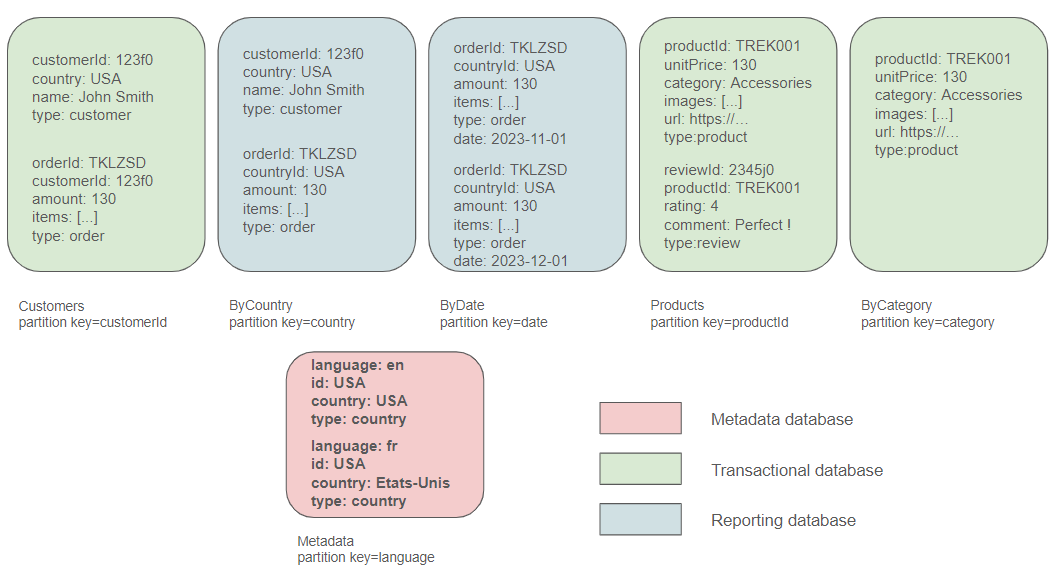
In real-world scenarios, Cosmos DB would be used for transactional workloads, storing and retrieving operational data, and then a dedicated analytical service for running complex queries and generating reports would be implemented (like BigQuery or Azure Synapse Analytics). This separation allows us to optimize each part of your architecture for its specific purpose – fast transactions in Cosmos DB and efficient analytics in the dedicated analytical store.
And for the unforeseen queries ?
Unanticipated queries are inevitable. In such instances, we will rely on the data available to us and make the best use of what we have. Given that these requests haven't been pre-defined, they are likely to be rare occurrences, allowing us to manage the associated costs and time invested.
As an illustration, suppose we wish to determine the quantity of shoes ordered on the site. To accomplish this, the initial step is to reformulate the inquiry and incorporate a specified date range within the query. Essentially, what the data scientist is seeking is the count of shoes ordered in the recent week or on a specific day, for instance, yesterday. In light of this requirement, the appropriate container to utilize would be the ByDate container.
However, there are instances where solutions may not be straightforward or readily attainable, necessitating the introduction of a new concept within one of the containers. This scenario arises, for instance, when there is an interest in the reviews submitted by a particular customer (we briefly dealt with this case earlier in this post). In such cases, where there isn't a readily apparent container to utilize, it becomes necessary to augment the Customers container by incorporating the review type.
Final thoughts
If you wish to delve deeper into this topic, acquire the following book, which encompasses all the concepts emphasized in this series and delves into more advanced ones.
NoSQL Distilled (Sadalage, Fowler)
Do not hesitate to contact me shoud you require further information.