Comparing K-Means and others algorithms for data clustering - Part 6
In this concluding post, we will explore the DBSCAN algorithm and demonstrate how it can be employed to alleviate the limitations of both K-Means and hierarchical clustering.
What is DBSCAN ?
Density-based spatial clustering of applications with noise (DBSCAN for short) is a popular clustering algorithm used in machine learning and was introduced in 1996. DBSCAN is particularly useful for identifying clusters of data points in spatial datasets based on the density of data points in the feature space. The key idea behind it is to define clusters as dense regions of data separated by areas of lower point density.
The algorithm works by starting with an arbitrary data point and expanding the cluster by adding all reachable points to the cluster. This process continues until no more core points can be added. The algorithm then selects another unvisited point and repeats the process, continuing until all data points have been visited.
What is a reachable point ?
The DBSCAN algorithm uses 2 parameters: the distance $\epsilon$ and the minimum number of points $MinPts$ that must be within a radius $\epsilon$ for these points to be considered as a cluster. Therefore, the input parameters provide an estimate of the density of points in the clusters. The basic idea of the algorithm is then, for a given point, to retrieve its $\epsilon$-neighborhood and check that it contains at least $MinPts$ points. This point is then considered to be part of a cluster. We then traverse the $\epsilon$-neighborhood step by step to find all the points in the cluster.
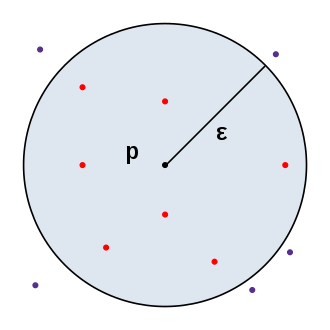
Shown here is an $\epsilon$-neighborhood of point $p$ represented in a 2-dimensional space with Euclidean distance. The red points are the $q$ data points that belong to the $\epsilon$-neighborhood of point $p$, and the violet points represent the $q$ data points that do not belong to the $\epsilon$-neighborhood of point $p$. For the DBSCAN algorithm, it is the number of red points that is significant.
- If $MinPts=3$ for example, then the considered neighborhood is clearly dense and forms a cluster.
- Conversely, if $MinPts=50$, then the neighborhood is clearly not dense and these points can be considered as noise.
With these definitions, a reachable point is a point within a dense neighborhood. Some violet points will be reachable in the image below (if $MinPts=3$ for example) and will consequently aggregate into the already established cluster.
Unlike K-Means and our version of hierarchical clustering, DBSCAN does not require specifying the number of clusters beforehand.
As implied by its name, DBSCAN considers outliers and effectively filters out noisy data points.
The choice of parameters ($\epsilon$ and $MinPts$) is very challenging and can have a significant impact on the clustering results. Careful parameter tuning is often required for optimal performance.
Implementation in C#
We need to implement the IClusteringStrategy interface.
1public class DBSCANClusteringStrategy : IClusteringStragtegy
2{
3 public List<DataCluster> Cluster(Dataset set, int clusters)
4 {
5 var results = new List<DataCluster>();
6
7 var eps = ComputeEpsilon(set);
8 var minPts = ComputeMinPoints(set, eps);
9
10 var c = 0;
11 var visitedPoints = new List<DataPoint>(); var noisePoints = new List<DataPoint>();
12 foreach (var point in set.Points)
13 {
14 if (visitedPoints.Contains(point)) continue;
15
16 visitedPoints.Add(point);
17
18 var neighbors = GetNeighbors(set, point, eps);
19 if (neighbors.Count < minPts)
20 {
21 noisePoints.Add(point);
22 continue;
23 }
24
25 c++;
26 var cluster = new DataCluster() { Cluster = c.ToString(), Points = new List<DataPoint> { point } };
27
28 var index = 0;
29 while (index < neighbors.Count)
30 {
31 var npoint = neighbors[index];
32
33 if (noisePoints.Contains(npoint)) noisePoints.Remove(npoint);
34
35 if (visitedPoints.Contains(npoint))
36 {
37 index++;
38 continue;
39 }
40 visitedPoints.Add(npoint);
41
42 var npointNeighbors = GetNeighbors(set, npoint, eps);
43 if (npointNeighbors.Count >= minPts)
44 {
45 foreach (var npointNeighbor in npointNeighbors)
46 {
47 if (!neighbors.Contains(npointNeighbor))
48 neighbors.Add(npointNeighbor);
49 }
50 }
51
52 cluster.Points.Add(npoint);
53 index++;
54 }
55
56 results.Add(cluster);
57 }
58
59 return results;
60 }
61
62
63 private List<DataPoint> GetNeighbors(Dataset set, DataPoint point, double eps)
64 {
65 var results = new List<DataPoint>();
66 foreach (var p in set.Points.Where(x => x != point))
67 {
68 if (p.ComputeDistance(point) <= eps)
69 results.Add(p);
70 }
71 return results;
72 }
73
74 private double ComputeEpsilon(Dataset set)
75 {
76 var distances = new List<double>();
77 foreach (var point in set.Points)
78 {
79 var distance = double.MaxValue;
80 foreach (var other in set.Points.Where(x => x != point))
81 {
82 var d = point.ComputeDistance(other);
83 if (d < distance)
84 {
85 distance = d;
86 }
87 }
88 distances.Add(distance);
89 }
90
91 var nb = (int)(distances.Count * 0.9);
92 return 2 * distances.OrderBy(x => x).Take(nb).Max();
93 }
94
95 private double ComputeMinPoints(Dataset set, double eps)
96 {
97 var numberPoints = new List<int>();
98 foreach (var point in set.Points)
99 {
100 var neighbors = GetNeighbors(set, point, eps);
101 numberPoints.Add(neighbors.Count);
102 }
103
104 var nb = (int)(numberPoints.Count * 0.9);
105 return numberPoints.OrderByDescending(x => x).Take(nb).Min();
106 }
107}
Results for the first dataset
Keep in mind that the first dataset is purely academic and serves as a straightforward test to ensure the algorithm functions on simple cases.
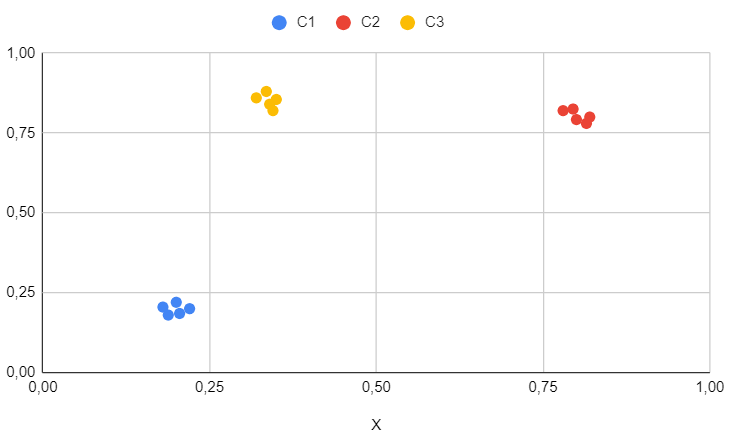
We can observe that, as expected, the clusters are perfectly identified and there is nothing noteworthy to mention here, except for the fact that the number of clusters has been determined without the necessity for explicit specification..
Results for the second dataset
The second dataset is employed to illustrate the impact of outliers.
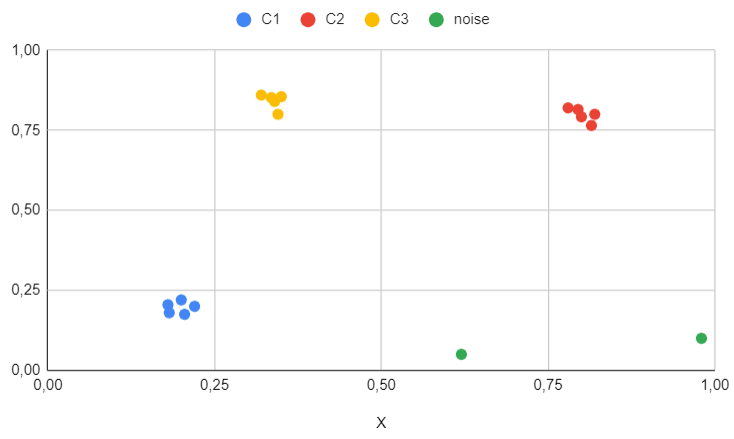
This is where DBSCAN excels: not only does it identify outliers, but it also eliminates them, categorizing them separately from specific clusters.
Results for the third dataset
The third dataset is used to demonstrate how the algorithm performs in more challenging or pathological cases.
In this case, there are two clusters (not three, as before).
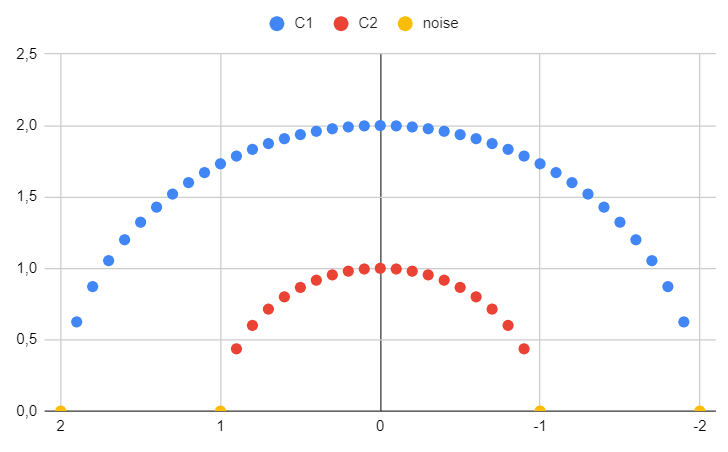
DBSCAN effectively addresses irregular shapes and remains unaffected by non-linearly separable data. Furthermore, it successfully detected four noise points (depicted in yellow) that are notably more distant than the rest.
DBSCAN is easy to comprehend, is quite intuitive and has some advantages such as its ability to handle clusters of varying shapes and sizes, and its ability to identify noise (outliers)
Moreover, it does not require specifying the number of clusters beforehand.
However, it may struggle with datasets of varying densities (the OPTICS algorithm was designed to alleviate this concern), and the choice of parameters ($\epsilon$ and $MinPts$) can have a significant impact on the clustering results. Careful parameter tuning is often required for optimal performance.
Final thoughts
If you wish to delve deeper into this topic, acquire the following books, which encompass all the concepts emphasized in this series and delve into more advanced ones.
Pattern Recognition and Machine Learning (Bishop)
Machine Learning: An Algorithmic Perspective (Marsland)
Probabilistic Machine Learning: An Introduction (Murphy)
Probabilistic Machine Learning: Advanced Topics (Murphy)
Mining of Massive Datasets (Leskovec, Rajaraman, Ullman)
Do not hesitate to contact me shoud you require further information.