Comparing K-Means and others algorithms for data clustering - Part 5
In this post, we continue our exploration by examining the characteristics of hierarchical clustering.
What is hierarchical clustering ?
Hierarchical clustering is a clustering algorithm that creates a hierarchy of clusters. The algorithm iteratively merges or divides clusters based on the similarity or dissimilarity between them until a predefined stopping criterion is met.
There are two main types of hierarchical clustering: agglomerative or divisive.
Agglomerative hierarchical clustering starts with each data point as a separate cluster and successively merges the closest pairs of clusters until only one cluster remains. The merging process is often based on distance measures like Euclidean distance.
Divisive hierarchical clustering starts with all data points in a single cluster and recursively divides the cluster into smaller clusters until each data point is in its own cluster. Similar to agglomerative clustering, divisive clustering uses distance measures or linkage criteria for the splitting process.
We will only implement an agglomerative hierarchical clustering in this post.
In theory, hierarchical clustering is advantageous in that it doesn't require specifying the number of clusters beforehand. However, it requires for that a stopping criterion that is not easy to determine organically. Therefore, in this post, we will predefine the number of clusters to be identified.
How to implement hierarchical clustering ?
Imagine a situation in which we need to cluster the following dataset.
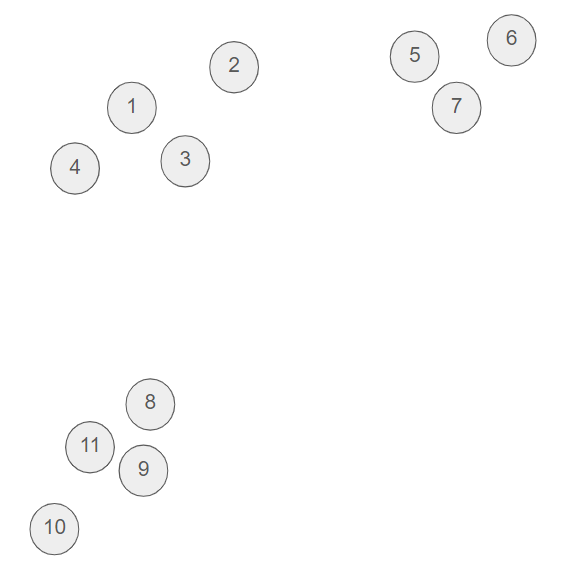
We start with each point in its own cluster (in our case, we thus start with 11 clusters). Over time, larger clusters will be formed by merging two smaller clusters. But how do we decide which two clusters to merge ? We will delve into that in the next section, but for now, the algorithm can be described as follows.
1WHILE we have the right number of clusters DO
2 pick the best two clusters to merge
3 combine those clusters into one cluster
4END
How do we decide which two clusters to merge ?
In fact, there are several rules for selecting the best clusters to merge. In this post, we will use the minimum of the distances between any two points, with one point chosen from each cluster. Other rules are possible; for example, we could identify the pair with the smallest distance between their centroids.
- According to our rule, the two closest clusters are 9 and 11, so we merge these two clusters.
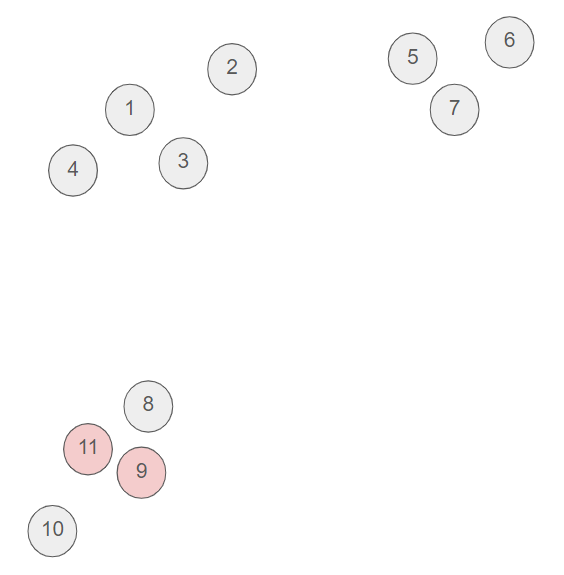
- Now, we chose to cluster the point 8 with the previous cluster of two pints (9 and 11) since the point 8 and 9 are very close and no other pair of unclustered points is that close.
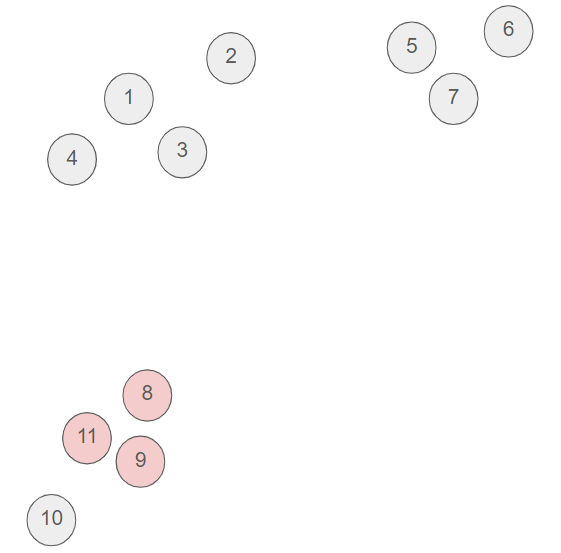
- Then, we chose to cluster the point 5 and 7.
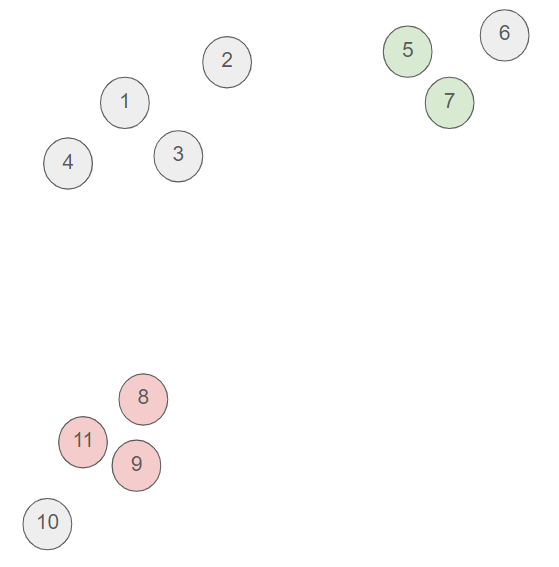
- And so forth until we have reached the desired number of clusters.
Implementation in C#
We need to implement the IClusteringStrategy interface.
1public class HierarchicalClusteringStrategy : IClusteringStragtegy
2{
3 public List<DataCluster> Cluster(Dataset set, int clusters)
4 {
5 var results = new List<DataCluster>(); var c = 1;
6 foreach (var point in set.Points)
7 {
8 var cluster = new DataCluster()
9 {
10 Cluster = c.ToString(),
11 Points = new List<DataPoint> { point }
12 };
13 results.Add(cluster);
14
15 c++;
16 }
17
18 var currentNumber = results.Count;
19 while (currentNumber > clusters)
20 {
21 var minimum = double.MaxValue; var clustersToMerge = new List<DataCluster>();
22 foreach (var cluster in results)
23 {
24 var remainingClusters = results.Where(x => x != cluster).ToList();
25 foreach (var remainingCluster in remainingClusters)
26 {
27 //var distance = cluster.GetCentroid().ComputeDistance(remainingCluster.GetCentroid());
28 var distance = ComputeDistanceBetweenClusters(cluster, remainingCluster);
29 if (distance < minimum)
30 {
31 minimum = distance;
32 clustersToMerge = new List<DataCluster>() { cluster, remainingCluster };
33 }
34 }
35 }
36
37 // Merge clusters
38 var newCluster = new DataCluster()
39 {
40 Cluster = clustersToMerge.Select(x => Convert.ToInt32(x.Cluster)).Min().ToString(),
41 Points = clustersToMerge.SelectMany(x => x.Points).ToList()
42 };
43
44 foreach (var delete in clustersToMerge)
45 results.Remove(delete);
46
47 results.Add(newCluster);
48 currentNumber = results.Count;
49 }
50
51 return results;
52 }
53
54 private double ComputeDistanceBetweenClusters(DataCluster dataCluster1, DataCluster dataCluster2)
55 {
56 var minimum = double.MaxValue;
57 foreach (var point1 in dataCluster1.Points)
58 {
59 foreach (var point2 in dataCluster2.Points)
60 {
61 var distance = point1.ComputeDistance(point2);
62 if (distance < minimum)
63 {
64 minimum = distance;
65 }
66 }
67 }
68
69 return minimum;
70 }
71}
Results for the first dataset
Keep in mind that the first dataset is purely academic and serves as a straightforward test to ensure the algorithm functions on simple cases.
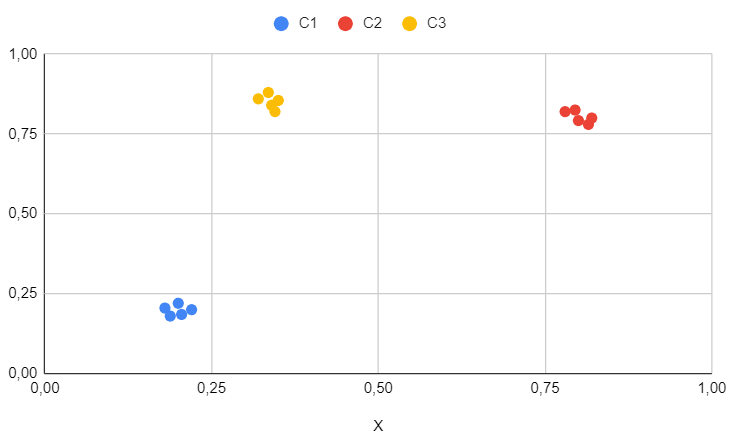
We can observe that, as expected, the clusters are perfectly identified and there is nothing additional to note regarding this specific case.
Results for the second dataset
The second dataset is employed to illustrate the impact of outliers.
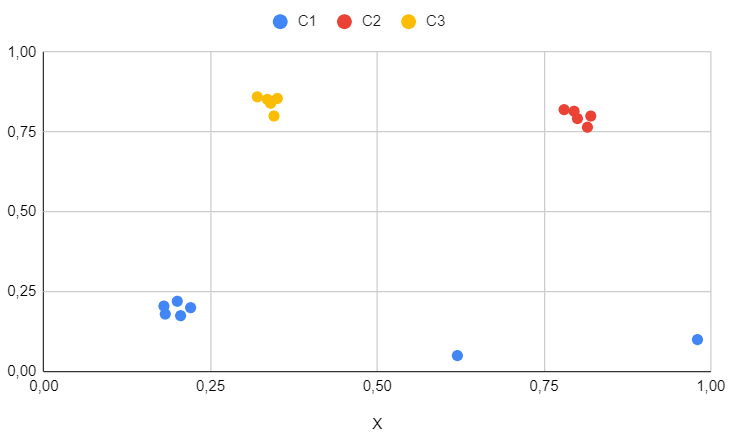
Despite the existence of outliers, it is evident that hierarchical clustering responds appropriately and effectively identifies precise clusters. Consequently, hierarchical clustering demonstrates greater resilience to outliers compared to K-Means.
Results for the third dataset
The third dataset is used to demonstrate how the algorithm performs in more challenging or pathological cases.
In this case, there are two clusters (not three, as before).
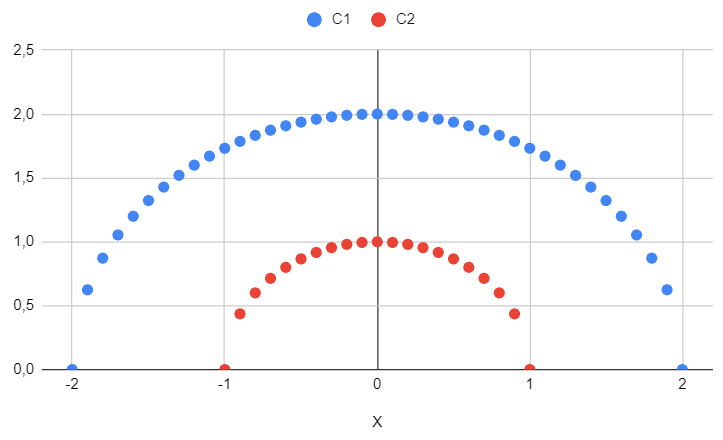
Thus, hierarchical clustering appears to adeptly handle irregular shapes and is not impeded by data that is not linearly separable.
Hierarchical clustering is easy to comprehend and implement and is quite robust to outliers. Additionally, it seems well-suited for datasets with irregular shapes.
Moreover, hierarchical clustering is easy to understand and implement, and it is quite robust to outliers. Additionally, it appears well-suited for datasets with irregular shapes. Hierarchical clustering seems like a magical method, prompting the question of why it is not more widely used. However, a key point is not evident in the preceding examples: hierarchical clustering can be computationally intensive and less suitable for large datasets compared to methods like K-Means.
The algorithm for hierarchical clustering is not very efficient. At each step, we must compute the distance between each pair of clusters, in order to find the best merger. The initial step takes $O(n^2)$ time [$n$ is the number of records in the dataset], but the subsequent steps take time time proportional to $(n-1)^2$, $(n-2)^2$, ... The sum of squares up to $n$ is $O(n^3)$, so the algorithm is cubic. Thus, it cannot be run except for fairly small numbers of points.
Leskovec, Rajaraman, Ullman (Mining of Massive Datasets)
Even though more optimized versions of this algorithm exist (especially those incorporating priority queues), the execution time is still relatively high. As a result, this method can be employed only for small datasets.
Can we improve and address some of the limitations mentioned here ? This is the topic of the next article dedicated to DBSCAN.