Building resilient .NET applications with Polly - Part 2
In this post, we elucidate the reasons why distributed architectures, in particular, can succumb to chaos when not meticulously designed, and we explore strategies to circumvent and mitigate these issues.
A single dramatic software failure can cost a company millions of dollars but can be avoided with simple changes to design and architecture.
Nygard Release It!: Design and Deploy Production-Ready Software
What are distributed architectures ?
Distributed architectures refer to a system design in which components or modules of a software application are distributed across multiple computers or servers, often geographically dispersed. Unlike a traditional monolithic architecture where all components are tightly interconnected and reside on a single platform, distributed architectures distribute the workload and functionality among various nodes in a network.
Common examples of distributed architectures include microservices architectures and their main goal is to enhance scalability, improve performance, and increase reliability by leveraging the capabilities of multiple interconnected systems. For a more in-depth exploration of all the challenges and intricacies associated with implementing microservices serverless architectures, we encourage the reader to refer to our dedicated post on the subject (How to implement a serverless architecture on Azure).
The figure below illustrates an example of a distributed architecture.
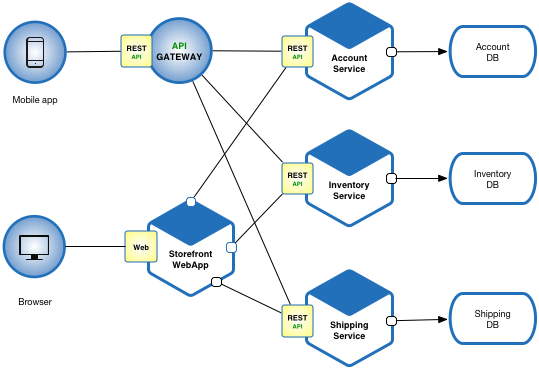
What occurs in the event that one of the components becomes unresponsive?
At the risk of sounding like broken record, I'll say it again: expect failures.
Nygard Release It!: Design and Deploy Production-Ready Software
Continuing with the aforementioned example, what are the potential consequences if the Account service experiences a delay ?
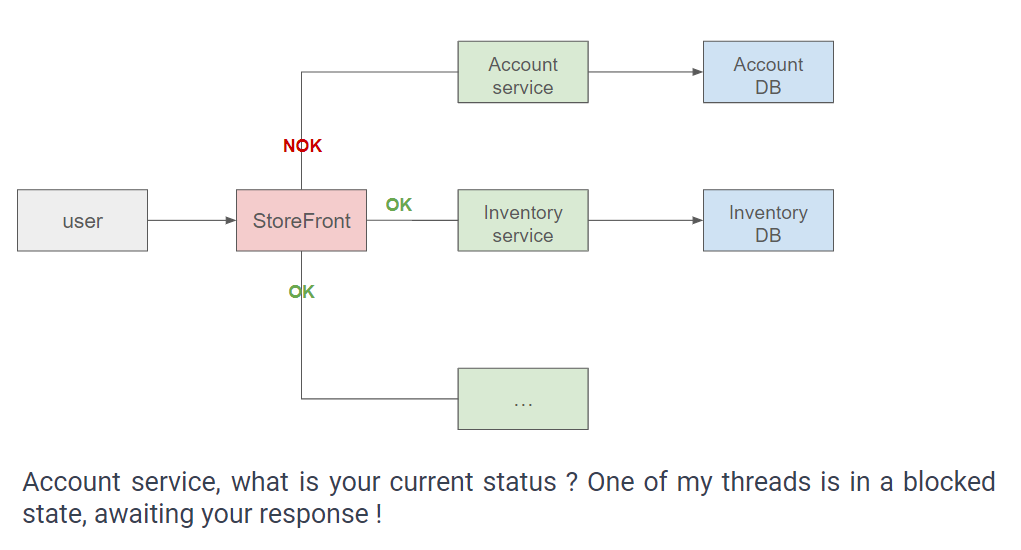
A user initiates an attempt to visit a page within the StoreFront application.
Subsequently, the application allocates a new thread to handle this request and endeavors to establish communication with various services, including the Account service.
The Account service is unresponsive, so the thread tasked with processing the request becomes suspended, desperately awaiting a response from the server. Regrettably, it is unable to execute any other tasks during this period of delay.
When another user accesses the site, the application allocates a thread to manage the new request. However, a similar scenario unfolds as this thread also becomes suspended, attributable to the unresponsiveness of the Account service. The consecutive request is consequently affected by the service downtime.
This cycle persists repeatedly until no more threads are available to handle new requests. In certain cloud platforms, additional instances of the StoreFront application may be deployed as a workaround. However, they encounter identical issues, resulting in numerous servers awaiting responses, all with blocked threads. To exacerbate the situation, these servers incur charges from the cloud platforms, all stemming from the unavailability of a single service.
This type of issue can manifest even if the Account service is not the primary instigator, such as when the Account database experiences unresponsiveness.
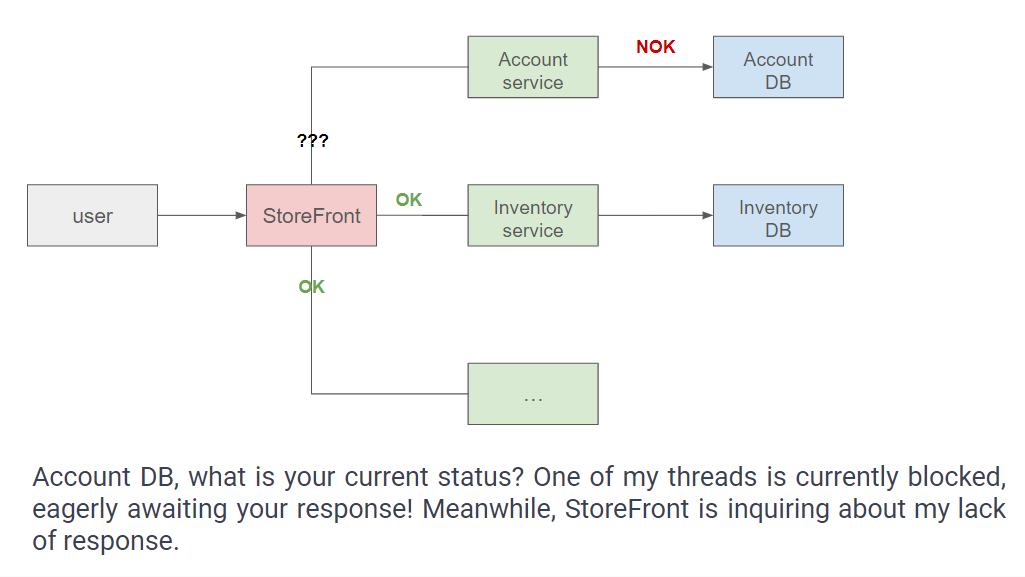
Each time the Account service requires information from this database, it allocates a thread, which, in turn, becomes suspended due to the database failure. Consequently, all threads within the Account service become occupied, awaiting responses, leading back to the previous scenario where the Account service begins to hang.
These illustrations exemplify chain reactions and cascading failures, where a disruption in one layer initiates a corresponding disruption in a calling layer.
An obvious example is a database failure. If an entire database cluster goes dark, then any application that calls the database is going to experience problems of some kind. What happens next depends on how the caller is written. If the caller handles it badly, then the caller will also start to fail, resulting in a cascading failure. (Just like we draw trees upside-down with their roots pointing to the sky, our problems cascade upward through the layers.)
Nygard Release It!: Design and Deploy Production-Ready Software
What is the issue at hand, precisely ?
In our scenario, the issue emerges when one of the components experiences a breakdown. However, fundamentally, this situation arises whenever we need to access another resource within the platform or the farm. The moment multiple servers are involved in the process, as is common in distributed architectures, there is an increased risk of encountering complications. These potential failure points are identified as integration points: integration points are the myriad connections between two computers.
- An integration point can encompass a connection between a web application and a service.
- It can encompass a connection between a service and a database.
- It can encompass any HTTP request taking place within the application.
Distributed systems pose thus unique challenges related to communication, data consistency, fault tolerance, and overall system complexity. Effective design and implementation are crucial to harness the benefits of distribution while mitigating the potential challenges associated with it.
Fortunately, there are established patterns and best practices to mitigate such issues. Common data structures can be employed to circumvent challenges, and even more advantageous is the existence of a library where everything is pre-implemented, sparing the need for manual implementation. The next post will delve into the presentation of this library.