Comparing K-Means and others algorithms for data clustering - Part 2
In this post, we offer a concise overview of clustering, delve into the accompanying challenges, and introduce various state-of-the-art algorithms.
What is clustering ?
Clustering is a technique in machine learning and data analysis that involves grouping a set of data points into subsets or clusters based on their inherent similarities. The primary goal of clustering is to organize and uncover patterns within the data, allowing for the identification of meaningful structures or relationships.

The process involves partitioning the data into groups in such a way that data points within the same cluster are more similar to each other than to those in other clusters. Similarity is typically measured using distance metrics, and various algorithms, such as K-Means, hierarchical clustering, and DBSCAN, are employed to perform clustering tasks. For example, it seems quite natural to identify three distinct clusters that are clearly separated in the figure above.
However, clustering can sometimes become more challenging, as illustrated in the example below, where the clusters exhibit more irregular shapes and are not easily separable by linear boundaries.

What characteristics should a clustering algorithm possess ?
The typical response is, as always: it varies. It genuinely depends on the specific application in question. In practical terms, certain algorithms excel in certain situations while performing inadequately in others. Some algorithms may demonstrate adaptability to challenging scenarios but come with a high computational cost. In this section, our aim is to highlight the characteristics that are frequently essential.
To ensure maximum conciseness, our study will focus exclusively on continuous input variables, considering only Euclidean spaces where distances and angles can be defined. This restriction is due to the fact that certain algorithms involve the computation of point averages, a task that is notably more straightforward in Euclidean spaces.
While the algorithms we are about to introduce don't strictly require a Euclidean space, they universally rely on a concept of distance to calculate the similarity or dissimilarity between points. For instance, when dealing with documents, clustering based on edit distance is feasible, but assigning meaning to the average of multiple documents becomes a more intricate task.
| document 1 | document 2 | document 3 |
|---|---|---|
| Microsoft Corporation, commonly known as Microsoft, is an American multinational technology company that produces, licenses, and sells computer software, consumer electronics, and other personal computing and communication products and services. Microsoft is one of the world's largest technology companies, founded by Bill Gates and Paul Allen in 1975. | Amazon.com, Inc. is an American multinational technology and e-commerce company based in Seattle, Washington. Founded by Jeff Bezos in 1994, Amazon started as an online bookstore and has since diversified into various product categories and services. It is one of the world's largest and most influential technology companies. | Renault is a French multinational automotive manufacturer established in 1899. The company produces a range of vehicles, from cars and vans to trucks and buses. Renault is known for its diverse lineup of vehicles and has a significant presence in the global automotive market. The company has been involved in various collaborations and partnerships with other automakers over the years. Additionally, Renault has a strong presence in motorsports and has achieved success in Formula One racing. |
What is the mean of these three documents ? Is it even feasible to establish a definition for it ?
We excluded categorical features for similar reasons. Consider a dataset with records featuring a "Country" attribute, for instance.
| Country |
|---|
| USA |
| France |
| Greece |
What is the mean of these three countries ?
How will we compare algorithms ?
Our objective in this series is to assess various state-of-the-art algorithms, and we will achieve this by utilizing straightforward predefined datasets consisting of only two features, X and Y.
- The first dataset is the most basic and will allow us to observe how the algorithms perform in straightforward scenarios.

- The second dataset is nearly identical but incorporates two outliers, providing insight into algorithm behavior in the presence of outliers.

- Lastly, the third dataset explores algorithm performance when data is not linearly separable or exhibits irregular shapes.

The goal is to assess how each analyzed algorithm performs with these three datasets and determine the relevance of the resulting clusters. Specifically, we will delve into the following questions in great detail.
Is it necessary to predefine the number of clusters ?
Determining the appropriate number of clusters has consistently posed a challenge, leading some algorithms, such as the well-established K-Means, to require this number as an input. This necessitates having a prior understanding of the potential number of groups within the dataset.
It's important to note that this requirement is not necessarily a drawback, as specifying the number of clusters can align with specific business requirements.
On the contrary, other algorithms do not enforce a predetermined number of clusters; instead, they autonomously determine it as part of their inherent process.
What does sensitivity to outliers entail ?
Outliers are data points that deviate significantly from the rest of the dataset, often lying at an unusual distance from the central tendency of the distribution. These data points are considered unusual or atypical compared to the majority of the other observations in the dataset. Outliers can influence statistical analyses and machine learning algorithms, potentially leading to skewed results or biased models. Identifying and handling outliers is crucial in data preprocessing to ensure the robustness and accuracy of analytical processes.
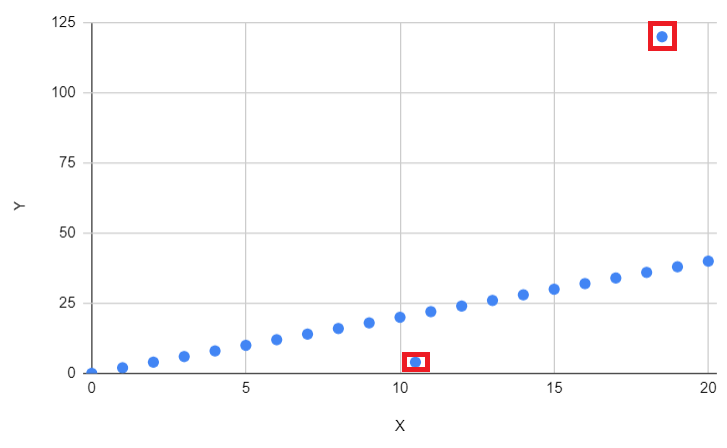
The second dataset will enable us to observe how sensitive algorithms are to outliers.
What occurs when the data exhibits irregular shapes ?
The majority of algorithms operate effectively with linearly separable data, meaning data that can be divided by straight lines or planes. However, situations may arise where the data displays irregular or degenerate shapes, as illustrated in the figure below. In such cases, does the algorithm possess the capability to accurately cluster the dataset ?

Is the implementation of the algorithm straightforward, and does it demonstrate efficiency ?
Last but not least, it is crucial to assess whether the algorithm can be easily implemented and comprehended in a specific programming language. An algorithm that is overly intricate, requiring exceptional mathematical skills or proving challenging to articulate, might not find widespread utility.
Equally important is its efficiency. Once again, the question arises: how valuable is a highly efficient method capable of handling outliers or distinguishing irregular shapes if its computational complexity is exponential ?
In this series, we will endeavor to scrutinize each of these characteristics for the algorithms under study. This approach will provide a clearer insight into the strengths and weaknesses of each algorithm.
Which algorithms are we going to analyze ?
There exists a multitude of clustering algorithms and various versions of each. In this context, we will focus on three specifically: firstly, the widely utilized K-Means, followed by hierarchical methods, and finally, the often underestimated DBSCAN technique.